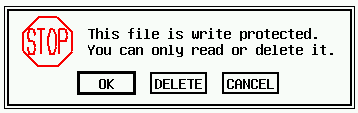
Okno ALERT z wiadomością.
Programowanie w języku X11-BASIC
STRESZCZENIE
Większą część pracy stanowi opis języka programowania X11-Basic, sposoby instalacji i korzystania, opis komend. Zawiera również uwagi dotyczące szybkości działania programów, przykłady ich optymalnej implementacji, porównanie z innymi językami programowania. Na końcu zawarty jest krótki opis gry napisanej w X11-Basic oraz uwagi dotyczące korzystania z tego języka.
ABSTRACT
Most of the work is the description of the X11-Basic programming language, installation and use methods, command description. It also includes notes on the speed of programs, examples of their optimal implementation, comparison with other programming languages. Finally, there is a brief description of the game written in X11-Basic and notes on using this language.
Spis treści
INFORMACJE O X11-BASIC - PRZENOŚNOŚĆ
Tworzenie i modyfikacja programów
Operatory porównania, <, <=, =, =>, >, <>
Proste wprowadzanie i wyprowadzanie danych
Formatowanie wyjścia za pomocą polecenia PRINT USING
Kontrola przebiegu programu – pętle i warunki
Diagnostyka błędów w czasie wykonywania
Odczytywanie i zapisywanie danych z plików
Połączenia internetowe i Bluetooth, specjalne pliki i gniazda
Lokalna komunikacja między procesami: potoki
Ogólnodostępna komunikacja: gniazda
Dane w kodzie źródłowym programu
Użycie funkcji C w bibliotekach współdzielonych
Graficzny interfejs użytkownika
Obiekty graficznego interfejsu użytkownika
Z jakiej metody danych wejściowych CGI należy korzystać
Polecenia wejścia / wyjścia konsoli tekstowej
Polecenia wejścia / wyjścia dla plików
Polecenia dotyczące manipulacji pamięcią
Polecenia graficznego interfejsu użytkownika
Funkcje wprowadzania i wyprowadzania plików
Funkcje zmiennych i przetwarzania łańcuchów
Luki w teorii złożoności obliczeniowej
Tematem niniejszej pracy będzie zaprezentowanie możliwości języka X11-BASIC oraz prostej gry działającej w systemie Android stworzonej w tym języku.
Język BASIC staje się coraz mniej popularny, prawdopodobnie jest to spowodowane panującą opinią, iż jest to język prosty, o małych możliwościach. Jest to opinia błędna, wynikająca z faktu, że jest on zwykle kojarzony z erą domowych komputerów 8-bitowych lat osiemdziesiątych, w które był wbudowany. Jednak wraz z rozpowszechnieniem się komputerów 16- i 32-bitowych pojawiały się odmiany języka BASIC nowej generacji, które przy zachowaniu stosunkowo prostej i łatwej do przyswojenia składni posiadały znacznie więcej funkcji i potrafiły wykorzystywać możliwości nowoczesnych systemów operacyjnych. Takim właśnie językiem jest X11-BASIC.
X11-Basic obsługuje grafikę, dźwięk, a także wszystkie funkcje oferowane przez tradycyjne dialekty BASIC. Jest zatem odpowiedni do programowania skryptów powłoki, CGI, a także do obliczania złożonych algorytmów matematycznych, wizualizacji i graficznej reprezentacji wyników. Programy BASIC są zwykle dobrze zorganizowane. X11-Basic, podobnie jak inne nowoczesne dialekty BASIC, jest językiem strukturalnym i nie używa numerów linii.
Składnia X11-Basic jest wzorowana na składni GFA-Basic powstałego dla komputerów ATARI ST i jest zbliżona do stosowanej przez firmę Microsoft w QBASIC czy Visual Basic.
X11-Basic nadaje się do wszelakich zadań programistycznych, dla nauki i technologii, jest wykorzystywany do kompleksowych symulacji, sterowania oraz automatyzacji, oferuje wysoki poziom abstrakcji w dialekcie językowym, ale równie dobrze nadaje się do zadań sprzętowych i analizy danych. Jego dialekt językowy jest znacznie łatwiejszy do odczytania, zrozumienia i przyswojenia niż innych języków programowania, wg mnie jest znacznie łatwiejszy do nauczenia od popularnego aktualnie języka Python, dlatego jest szczególnie polecany osobom nie będącym zawodowymi programistami. X11-Basic umożliwia szybkie tworzenie kompaktowych, wydajnych, niezawodnych, czytelnych, przenośnych, dobrze skonstruowanych programów, powinien więc doskonale nadawać się do urządzeń przenośnych, które często posiadają ograniczone zasoby w stosunku do komputerów biurkowych i nie ma sensu stosowania w nich rozbudowanych środowisk programistycznych.
X11-Basic obsługuje liczby zespolone i złożone obliczenia matematyczne z dowolnie wybraną dokładnością, jak również bardzo szybkie operacje na 32-bitowych liczbach całkowitych i 64-bitowych zmiennoprzecinkowych. Ponadto operacje na dowolnej długości łańcuchów, na macierzach i.t.d.
Dzięki X11-Basic można szybko napisać małą aplikację przy niewielkim wysiłku, ozywać komend powłoki do uruchamiania innych programów, wykorzystywać biblioteki systemowe, które mogą być dołączane dynamicznie. Można również wykorzystywać wstawki w języku C i asemblerze.
Ponieważ jest to język interpretacyjny, każdy nowy krok w programie może zostać szybko przetestowany. Po ukończeniu programu można użyć kompilatora, aby utworzyć bardzo szybki, niezależnie wykonywalny program.
INFORMACJE O X11-BASIC - PRZENOŚNOŚĆ
Dialekt X11 Basic został zaprojektowany tak, aby był jak najbardziej niezależny od platformy. Możesz więc oczekiwać, że programy X11 Basic będą działać na wielu systemach operacyjnych, robiąc to samo i tworząc wszędzie taki sam wygląd. Programy X11 Basic są przenośne.
X11-Basic jest przeznaczony do pracy w wielu systemach operacyjnych o niskich zasobach. Został pierwotnie opracowany dla stacji roboczych UNIX i systemów Linux z systemem X Window (stąd nazwa X11, którą wtedy oznaczano X oparty na głównej wersji 11). Wkrótce jednak wersje X11-Basic zostały również utworzone dla innych systemów operacyjnych (MS WINDOWS, MAC OSX, ATARI ST / TOS).
W przypadkach, gdy systemu graficzny X Window jest niedostępny X11-Basic może być skompilowany z wykorzystaniem graficznego urządzenia framebuffer. Na przykład wersja dla systemu Android używa interfejsu bufora ramki, taka implementacja jest też możliwa dla urządzeń nawigacyjnych TomTom i dla Raspberry Pi (bez X). Jako alternatywny silnik graficzny jest również obsługiwana biblioteka SDL (Simple Direct-Media Library), korzysta z niej wersja MS Windows, ale możliwe jest również skompilowanie obsługi SDL dla innych systemów operacyjnych w X11-Basic.
Tak więc możliwe jest również portowanie X11-Basic na bardzo prostych systemach, tak zwanych osadzonych (wbudowanych), z bardzo małą ilością pamięci RAM i niską wydajnością procesora.
Wreszcie możliwe jest nawet skompilowanie wersji X11-Basic bez grafiki. W ten sposób tworzony jest bardzo lekki silnik skryptowy, np. do budowy serwerów.
Dźwięk nie jest dostępny w każdym systemie. Tam, gdzie jest to możliwe, X11-Basic wykorzystuje 16-kanałowy syntezator dźwięku i możliwość odtwarzania próbek dźwięku ze standardowych formatów plików dźwiękowych (takich jak .wav i .ogg). W systemach LINUX odbywa się to głównie za pomocą silnika dźwięku ALSA. W systemie Android X11-Basic dodatkowo wykorzystuje sinik dźwiękowy i mowy.
Biblioteka X11 Basic zawiera graficzny interfejs użytkownika (GUI) wzorowany na GEM . Dzięki temu pisanie programów GUI w X11-Basic jest szybsze, łatwiejsze i bardziej mobilne niż programowanie za pomocą natywnych narzędzi GUI.
Wersja X11-Basic dla systemu Android zawiera w pełni funkcjonalną emulację terminala VT100 / ANSI oraz obsługę zestawów znaków Unicode (kodowanych w UTF-8) na standardowym wyjściu tekstowym.
X11-Basic jest darmowym oprogramowaniem rozpowszechnianym na licencji GNU.
Interpreter X11 Basic jest nazwany xbasic (xbasic.exe pod Windows), kompilator xbc (xbc.exe w systemie Windows), w systemach Unix te pliki wykonywalne są zwykle instalowane w /usr/bin/(jeśli są instalowane za pośrednictwem systemu zarządzania pakietami) lub w ścieżce /usr/local/bin (jeśli są instalowane ręcznie przez pakiet źródłowy). W systemie Windows pliki są zwykle instalowane w katalogu C:\x11basic lub C:\Program files\x11basic. W systemie Android nie musisz się martwić o poszczególne składniki X11-Basic, ponieważ aplikacja X11-Basic jest wyposażona w małe IDE (Integrated Development Environment), które obsługuje terminal, edytor, ładowanie, uruchamianie i kompilowanie.
Instalacja na urządzeniach z systemem Android jest bardzo prosta: zlokalizuj i zainstaluj aplikację X11-Basic w Sklepie Play. Po otwarciu aplikacji możesz wprowadzać poszczególne polecenia bezpośrednio za pomocą klawiatury, które są natychmiast wykonywane. Aby załadować program, naciśnij MENU-> load, wybierz plik z rozszerzeniem .bas, a następnie uruchom poleceniem MENU-> run.
Instalacja w systemie Linux (opartym na Debianie) jest nie mniej prosta: pobierz pakiet X11-Basic (odpowiedni plik .deb), kliknij go dwukrotnie w menedżerze plików i zainstaluj. Alternatywnie można użyć pakietu .deb nawet w terminalu za pomocą polecenia
dpkg -i xxx.deb
Uruchom interpreter z menu aplikacji lub bezpośrednio z powłoki poleceniem
xbasic
lub
xbasic mojprogram.bas
jeśli chcesz uruchomić program bezpośrednio.
Pobierz plik .zip z pakietu instalacyjnego i rozpakuj go w swoim katalogu użytkownika. Następnie uruchom rozpakowany program instalacyjny. W przypadku najnowszej wersji pobierz program instalacyjny zamiast pliku .zip.
X11-Basic instaluje się teraz na partycji C: w katalogu X11-Basic. Znajdziesz w nim między innymi interpreter xbasic.exe i kompilator xbc.exe, które możesz uruchomić dwukrotnym kliknięciem lub przeciągnięciem programu .bas.
Tworzenie i modyfikacja programów
Programy X11-Basic są plikami tekstowymi z rozszerzeniem .bas. Musisz go utworzyć za pomocą oddzielnego edytora tekstu, który nie jest zintegrowany z interpreterem X11-Basic.
Warto również zauważyć, że po zainstalowaniu edytora w systemie Android można uzyskać dostęp do edytora wybranego bezpośrednio z aplikacji X11 Basic za pomocą MENU-> Editor. Po zakończeniu edytora program jest automatycznie ładowany do X11-Basic, dzięki czemu można go od razu uruchomić.
Przykładowy tekst programu:
PRINT "Hallo" PAUSE 10 END
zapisz go w pliku hello.bas.
W systemie Android załaduj plik za pomocą MENU->Load, a następnie MENU->Run aby uruchomić. W systemie Windows po prostu przeciągnij plik na interpreter xbasic.exe, upuść go i uruchomi się twój program. W systemie Linux otwórz terminal i wpisz xbasic hello.bas.
Istnieje możliwość kompilacji programów X11 Basic do postaci tzw. kodu bajtowego (bytecode), dzięki czemu działają one znacznie szybciej.
W systemach UNIX, Linux i Windows oddzielne programy są używane do kompilowania plików .bas i przekształcania ich w kod bajtowy lub autonomiczne pliki EXE.
Jeśli używasz WINDOWS, najwygodniejszym sposobem kompilacji programów X11 Basic jest uruchomienie kompilatora xbc.exe , który ma mały interfejs użytkownika. Również w systemie UNIX / Linux bardzo wygodne jest użycie menedżera kompilatora xbc z odpowiednimi opcjami wiersza poleceń (zwróć uwagę na opcję `-virtualm`).
Dla każdego etapu tłumaczenia istnieją odrębne programy, które to wykonują: xbbc, xb2c i xbvm:
|
|
Kompiluje programy X11 Basic (pliki .bas) w pliki bytecode (.b). |
|
|
potrafi tłumaczyć pliki kodu bajtowego na kod źródłowy C. |
|
|
jest maszyną wirtualną (interpreterem kodu bajtowego). |
Chodzi o to, aby zwiększyć szybkość wykonywania programów X11 Basic kompilując je do kodu bajtowego, który wciąż jest wykonywalny. Sam kod bajtowy jest interpretowany przez interpreter kodu bajtowego (nazywany również maszyną wirtualną). Ta wirtualna maszyna musi istnieć na komputerze docelowym, a następnie można w niej wykorzystać wszystkie programy kodu bajtowego. W ten sposób kompilator X11 Basic nie musi zajmować się różnymi architekturami maszyn docelowych, a także kod bajtowy może być wykonywany znacznie szybciej niż zinterpretowany kod źródłowy BASIC.
Od konwersji na kod bajtowy już tylko krok do asemblera lub kodu maszynowego. Nawet tłumaczenie na C lub JAVA lub inny język byłoby proste. Podobnie jak w przypadku JAVA kod bajtowy jest niezależny od platformy i może działać w każdym systemie, do którego została przeniesiona maszyna wirtualna.
Przykład użycia:
xbbc mojprogram.bas -o mojprogram.b xbvm mojprogram.b
Możliwe jest przetłumaczenie wygenerowanego kodu bajtowego na kod źródłowy C i na koniec skompilowanie kodu źródłowego C do wykonywalnego pliku binarnego (np. kompilatorem GNU C gcc ). W ten sposób końcowy program staje się rzeczywistym plikiem wykonywalnym w kodzie maszynowym, który jest (nieco) szybszy niż kod bajtowy interpretowany przez maszynę wirtualną.
Takie programy można łączyć z biblioteką dynamicznego środowiska wykonawczego (.so lub .dll) X11-Basic lub biblioteką statyczną (.a lub .lib). W końcu działają niezależnie od interpretera lub maszyny wirtualnej. Istnieją jednak pewne ograniczenia co do kodu, oznacza to, że nie można skompilować każdego programu, który można interpretować.
Wytworzony kod źródłowy C zależy od nagłówka pliku xb2csol.h (zwykle zainstalowany w /usr/include/x11basic/) oraz biblioteki x11basic.a lub libx11basic.so, która musi być obecna.
xb2c przetwarza plik wejściowy. Rozszerzenie pliku wejściowego jest zwykle .b (które powinno być kodem bajtowym utworzonym przez `xbbc`). Nazwa domyślnego pliku wyjściowego to 11.c, ale oczywiście możesz podać alternatywne nazwy za pomocą opcji -o.
Przykład użycia (wszystkie przykłady działają pod Linuksem):
xbbc myprogram.bas -o b.b
xbvm b.b
xb2c b.b -o 11.c
gcc 11.c -lm -lX11 -lx11basic -lasound -lreadline -lgmp \
-llapack -o a.out
Dla wygody możesz również wykonać następujące polecenie:
xbc -virtualm mojprogram.bas -o a.out
To dokładnie to samo. Pakiet X11 Basic jest dostarczany z kompilatorem X11 Basic xbc, który tworzy autonomiczne pliki binarne z kodu źródłowego X11 Basic. Może również tworzyć pliki obiektowe .o zwane obiektami współużytkowanymi (lub bibliotekami DLL) i kod bajtowy.
Pakiet X11 Basic zawiera również prosty konwerter bas2x11basic z ANSI Basic na X11 oraz gfalist do odczytywania programów .gfa, które są w dużym stopniu zgodne z X11-Basic.
W tym rozdziale przedstawione zostaną charakterystyczne cechy języka X11-Basic oraz niektóre komendy.
Program składa się z głównego bloku programu oraz podprogramów i funkcji. Główny blok programu to sekcja między pierwszą linią a słowem kluczowym END (lub QUIT). Kod w głównym bloku steruje logiką twojego programu.
Komendy znajdują się w poszczególnych liniach programu. Nie stosuje się dodatkowych znaków oznaczających początek i koniec instrukcji, nie ma konieczności stosowania wcięć w instrukcjach złożonych. Linie mozna przenieść do nowego wiersza (podzielić) za pomocą znaku \.
Przykład:
PRINT "Hello,"; \" that's it"
Jest traktowane jak:
PRINT "Hello,"; " that's it"
Komentarz można wstawić do kodu programu za pomocą instrukcji REM, skrótu ' lub #. Komentarze na końcu linii muszą być poprzedzone prefiksem !.
Przykład:
' To jest demonstracja komentarzyDO ! nieskończona pętlaLOOP ! bez niczego w środku
UWAGA
komentarzy na końcu linii nie można używać po DATA i REM.
PRINT służy do przekazywania danych na standardowe wyjście (ekran)
INPUT - do pobierania danych z wejścia (np. klawiatury) i podstawieniu ich do zmiennej
IF - polecenie warunkowe, jeśli warunek jest spełniony (wynik wyrażenia po IF jest różny od 0) - wykonywane są kolejne linie aż do ENDIF
UWAGA
X11 stosuje dwie podstawowe wartości logiczne: FALSE (fałsz) = 0 i TRUE (prawda) = -1.
GOTO powoduje skok do miejsca programu oznaczonego etykietą zakończoną dwukropkiem. Aktualnie nie jest podstawową instrukcją, jednak może być przydatna.
Przykład:
ponownie:INPUT "Proszę podać numer, ale nie 13:";aIF a=13PRINT "Och, oczywiście lubisz trzynaście!"PRINT "Ale proszę podać inny numer."GOTO ponownieENDIFPRINT " Dziękuję za ";a;"."
Zasięg zmiennych
X11-Basic stosuje dwa rodzaje zasięgu zmiennych: globalny (domyślny) i lokalny.
Zmienne globalne można zmieniać z dowolnego miejsca w programie i każda część programu może z nich korzystać. Wszystkie zmienne są domyślnie globalne i nie musi to być jawnie deklarowane.
Zmienne lokalne istnieją tylko w ramach określonej funkcji lub procedury i jej kontekstu. Zmienne lokalne muszą być zadeklarowane w ramach funkcji lub procedury, do której należą, za pomocą polecenia LOCAL. Poza tą konkretną procedurą lub funkcją po prostu nie istnieją lub, jeśli istnieje globalna zmienna o tej samej nazwie, odnoszą się one do różnych treści.
Interpreter X11 Basic rozpoznaje 64-bitowe zmiennoprzecinkowe zmienne, 32-bitowe zmienne całkowite, łańcuchy i tablice tych zmiennych o dowolnym wymiarze. Deklaracja zmiennych i ich typu nie jest konieczna (z wyjątkiem tablic → DIM), ponieważ interpreter rozpoznaje typ zmiennej po końcówce: 32-bitowe zmienne liczby całkowitej mają przyrostek %, dowolnie duże zmienne całkowite &, zespolone #, ciągi znaków $, tablice (). Zmienne bez rozszerzenia są interpretowane jako rzeczywiste zmienne 64-bitowe zmiennoprzecinkowe. Wskaźniki to liczby całkowite, wywołania funkcji lub wyniki są oznaczone symbolem @ . Wyrażenia logiczne są również typu całkowitego. Ważne jest, aby wiedzieć, że zmienne ze specjalnym przyrostkiem różnią się od tych bez (nawet jeśli reszta nazwy jest identyczna).
Przykłady:
x = 10.3 ! jest to zmienna liczbowa (zmiennoprzecinkowa 64-bitowa)
x$ = "Hello" ! to jest ciąg znaków
x% = 5 ! jest to (32-bitowa) zmienna całkowita
x& = 79523612688076834923316 ! jest to duża zmienna całkowita
x# = 3 + 4i ! jest to zmienna liczb zespolonych
@x ! to odwołanie do funkcji lub procedury x
x() = [1,2,3,4] ! ta bestia odnosi się do tablicy
Wszystko to są różne zmienne mimo takiej samej głównej części nazwy.
Tablice mogą posiadać dowolną wielkość i wymiar, który może być zmieniany bez zmiany zawartości tablicy. Możesz zdefiniować tablicę za pomocą polecenia DIM. Możesz także zdefiniować tablicę, przypisując ją w następujący sposób:
DIM b(10) a()=b()
jeśli b() jest już zwymiarowana, lub przez
a()=[1,2,3,4;6,7,8,9]
W tym przykładzie tworzona jest dwuwymiarowa tablica, kolumny macierzy są rozdzielane przecinkami, jak poprzednio, a wiersze przez ";".
Arytmetyka z dowolnym stopniem dokładności, zwana arytmetyką dużych liczb lub, czasami, arytmetyką z nieskończoną precyzją, oznacza, że obliczenia są wykonywane na liczbach, których cyfry dokładności są ograniczone tylko dostępną pamięcią komputera. Jest to przeciwieństwo zwykle stosowanej arytmetyki o stałej dokładności (np. 32-bitowej) lub arytmetyki zmiennoprzecinkowej, która również ma ograniczoną dokładność.
Obliczanie za pomocą takich liczb jest powolne i nie wszystkie funkcje są dostępne dla tego typu danych. Nieskończona precyzja jest stosowana, gdy prędkość arytmetyczna nie jest czynnikiem ograniczającym lub gdy wymagane są dokładne wyniki z bardzo dużymi liczbami. Znakomitym tego przykładem jest silna kryptografia. Zatem X11-Basic jest już na to dobrze przygotowany.
Typ danych z sufiksem & obsługuje tylko liczby całkowite. Od użytkownika (i nie jest to szczególnie trudne) zależy pisanie procedur na liczbach wymiernych (przy użyciu dwóch dużych liczb całkowitych, liczników i mianowników) oraz odpowiednich procedur dodawania, odejmowania, mnożenia i dzielenia ułamków. Liczby niewymierne z dowolną, ale ustaloną dokładnością, które wymagają reprezentacji zmiennoprzecinkowej, są (obecnie) nieobsługiwane.
Istnieją następujące operatory dla dużych liczb całkowitych w X11-Basic: + - * / = <> <> MOD i DIV. Funkcje ABS(), SQRT(), NEXTPRIME(), FACT(), PRIMORIAL(), FIB(), LUCNUM(), RANDOM(), ADD(), SUB(), MUL(), DIV(), MOD(), POWM(), ROOT(), GDC(), LCM(), INVERT(), MIN(), MAX() i wiele innych. Również STR$(), BIN$(), OCT$() i HEX$() działają z dużymi liczbami całkowitymi.
Dzięki tym funkcjom możesz już wykonywać pewne obliczenia dotyczące kryptografii i teorii liczb.
Zmienne zarówno normalnych typów liczbowych, jak i dużych liczb całkowitych mogą być używane w wyrażeniach i mieszane. Jeśli to konieczne, zostaną one przekształcone w odpowiednie typy. Trzeba tylko zdawać sobie sprawę z możliwej utraty precyzji.
Oto przykład użycia arytmetyki dużych liczb w X11-Basic do rozkładu dużej liczby na czynniki pierwsze:
Przykład:
' Faktoryzacja liczby (big) Integer na czynniki pierwsze' z X11-Basic >= V.1.23'DIM smallprimes&(1000000)CLR anzprimessmallprimes&(0)=2INC anzprimesINPUT "Podaj (dużą) liczbę: ",a&PRINT "Obliczanie liczb pierwszych do ";lim&;". Proszę czekać..."lim&=SQRT(a&) ! Limit, do którego są przeszukiwane liczby pierwszeFOR i=1 TO DIM?(smallprimes&())-1b&=NEXTPRIME(smallprimes&(i-1))EXIT IF b&>lim&smallprimes&(i)=b&NEXT ianzprimes=iPRINT "wyliczone ";anzprimes;" liczby pierwsze do: ";b&PRINT "Faktoryzacja:"PRINT a&;"=";FOR i=0 TO anzprimes-1WHILE (a& MOD smallprimes&(i))=0PRINT smallprimes&(i);"*";FLUSHa&=(a& DIV smallprimes&(i))lim&=SQRT(a&)WENDEXIT IF smallprimes&(i)>lim&NEXT iIF nextprime(a&-1)=a& or a&=1PRINT a&ELSE' Liczba jest zbyt duża i nie możemy być pewni,' czy jest to liczba pierwsza.PRINT "----niekompletny test-----";a&ENDIFEND
UWAGA
Zauważ, że listę małych liczb pierwszych można również wygenerować za pomocą sita. Zastosowana metoda opiera się na testach pierwszości (z funkcją NEXTPRIME()) i może nie być optymalna.
Dzięki X11-Basic możesz obliczyć funkcje trygonometryczne takie jak SIN() lub ATAN() lub logarytmy (LOG()). Operacje bitowe jak AND lub OR są również dostępne, MIN() i MAX() (minimum lub maksimum argumentu), MOD lub INT() (resztę z dzielenia lub część całkowita). Wiele innych instrukcji daje kompletny zestaw funkcji matematycznych.
Większość z tych funkcji może działać z różnymi wejściowymi typami danych. Na przykład możesz użyć funkcji SQRT() na liczbach zespolonych.
UWAGA
X11-Basic nie zapewnia specjalnych operatorów i funkcji dla wyrażeń logicznych. Można po prostu użyć sprzężeń bitowych np. AND, OR lub NOT, gdzie 0 (czyli wszystkie bity to 0) można interpretować jako fałsz, a -1 (czyli wszystkie bity to 1) jako prawda.
Istnieje kilka operacji, które można wykonać bezpośrednio na łańcuchach lub zmiennych łańcuchowych.
Operator plus, koniunkcja
Operator + dla łańcuchów łączy dwa łańcuchy. Ciągi połączone przez + są połączone bez przerw.
Przykład:
a$="X11"b$="-"c$="BASIC"d$=a$+b$+c$
daje ciąg " X11-BASIC ".
Operatory porównania, <, <=, =, =>, >, <>
Funkcje porównania należą do funkcji numerycznych (boolowskich), ponieważ wynikiem jest liczba, chociaż można ich używać z ciągami.
Przykład:
IF a$="X11"...ENDIFWynik=(a$<>"Hallo")
Porównanie łańcuchów jest zgodne z następującymi regułami:
1. Dwa ciągi są równe, jeśli pasują do siebie, tzn. wszystkie znaki są identyczne (w tym spacje i znaki interpunkcyjne).
Przykład:
"123 v fdh.-" = "123 v fdh.-"
2. Porównanie za pomocą operatorów większości i mniejszości działa w następujący sposób: porównuje po kolei znaki łańcuchów aż kod ASCII jednego z nich jest mniejszy lub łańcuch kończy się pierwszy, wtedy łańcuch ten jest mniejszy.
Przykład:
"X11">"X11" Wynik: 0"X11"<"x11" Wynik: -1"123"<"abc" Wynik: -1"123">"1234" Wynik: 0
Operator & powoduje, że wartość zmiennej łańcuchowej traktowana jest jak kod programu (komenda lub wyrażenie).
Przykład:
REM generuje dziesięć razy polecenie 'print a$'CLR ia$="print a$"label1:INC iIF i>10b$="label2"ELSEb$="label1"ENDIF&a$GOTO &b$label2:END
X11-Basic ma zwykłe funkcje wyodrębniania część napisu: LEFT$(), MID$() i RIGHT$().
Jeśli chcesz podzielić ciąg na części, powinieneś użyć polecenia SPLIT lub funkcji WORD$().
Istnieje szereg innych funkcji do przetwarzania ciągów, takich jak UPPER$() (konwertuje ciąg znaków na wielkie litery), INSTR() (znajdzie ciąg wewnątrz drugiego), CHR$() (konwertuje kod ASCII znaku), GLOB() (testowanie łańcucha w stosunku do wzorca) i więcej, np. SPACE$, STRING$, STR$, USING$, HASH$ ...
Oprócz typowego odwołania do pojedynczego elementu tablicy możliwe jest również uzyskanie dostępu do bloków macierzy za pomocą operatora dwukropka (:). Ten operator jest jak symbol zastępczy, by powiedzieć X11-Basic, że chcesz mieć wszystkie elementy określonego wymiaru lub wszystkie indeksy między dwiema określonymi wartościami. Wynikiem tej operacji nie jest wtedy pojedynczy element tablicy, ale tablica nazistów (prawdopodobnie innego wymiaru), którą można przypisać do innej zmiennej tablicowej. Załóżmy na przykład, że chcesz uzyskać dostęp do całego pierwszego wiersza macierzy, możesz napisać:
b()=a(1,:)
Załóżmy na przykład, że chcesz tylko pierwsze dwa elementy w pierwszym wierszu. Użyj następującej składni:
b()=a(1,1:2)
Tablice są przydatne nie tylko do przechowywania informacji w tabelach, ale także do wykonywania operacji na macierzach. Na przykład możesz użyć klasycznych operacji arytmetycznych + i - dla każdej tablicy w X11-Basic: To powoduje dodanie wektora i odjęcie zdefiniowane w klasycznych przestrzeniach wektorowych, które jest po prostu dodawaniem i odejmowaniem elementycznie.
W przypadku tablic dwuwymiarowych definiuje się również mnożenie macierzy. W przypadku wektorów można użyć operatora * do obliczenia iloczynu krzyżowego (w wyniku czego powstaje macierz) lub produktu skalarnego (jeśli mnoży się wektor kolumnowy z wektorem wiersza). Aby zamienić wiersze i kolumny istnieje funkcja TRANS(), która ma zastosowanie do całej tablicy.
Tabela 1. Operatory macierzy:
|
Operator tablicy |
opis |
|
+ |
Dodawanie wektorów / macierzy element do elementu |
|
- |
Odejmowanie wektorów / macierzy element od elementu |
|
* |
Mnożenie wektorów / macierzy |
|
: |
Podmacierz (blok) |
|
= <> |
Porównanie element po elemencie |
|
< > <= >= |
Porównanie wg normy |
Funkcje macierzowe i operatory działają na całych tablicach. Niektóre zwracają listę, która może być używana jako wartość innej funkcji tablicowej lub jako zmienna tablicowa.
Porównania tablic porównują treści tablicy element do elementu, używając domyślnej funkcji porównania dla typu danych elementu (=,>,<). W wielowymiarowych tablicach elementy są odwiedzane wg prządku "rzędu głównego" (ostatni indeks zmienia się najszybciej). Jeśli zawartość dwóch tablic jest taka sama, ale wymiarowość jest inna, pierwsza różnica w informacji o wymiarowości decyduje o kolejności sortowania.
Istnieją dwa typy podprogramów w X11-Basic: procedury i funkcje. Główna różnica między nimi polega na tym, że funkcja zwraca pojedynczą wartość i może być używana w wyrażeniach, podczas gdy procedura nie zwraca wartości i sposobu wywoływania polecenia. Po głównym bloku programu musi pojawić się procedura lub funkcja. Dlatego struktura programu X11 Basic wygląda następująco:
Główny blok programu
END ! lub QUIT
Procedury i funkcje
|
Procedury |
są
blokami kodu, które można wywoływać z innej lokalizacji w
programie. Te podprogramy mogą przyjmować argumenty, ale nie
zwracają wyników. Możesz uzyskać dostęp do wszystkich dostępnych
zmiennych, ale możesz także mieć zmienne lokalne (→
PROCEDURE nazwa(lista argumentów)
... wiele poleceń
RETURN
|
|
Funkcje |
są
blokami kodu, które można wywołać z innego miejsca w wyrażeniu
(np.:
FUNCTION nazwa(lista argumentów) .. Wiele obliczeń i poleceń RETURN zwracanawartość ENDFUNCTION
|
Alternatywą dla "FUNCTION" jest instrukcja "DEFFN", która definiuje funkcję jednoliniową, np.:
DEFFN Copy$(a$,p)=MID$(a$,p)
W przeciwieństwie do procedur i funkcji, funkcje DEFFN mogą być umieszczane w procedurze lub treści funkcji nawet jeśli nie używają zmiennych lokalnych podprogramu. Istnieje też inna różnica między DEFFN i FUNCTION: kompilator używa wyrażenia "DEFFN" jako wyrażenia wbudowanego i nie tworzy funkcji o nazwie symbolu. Jest to nieco szybsze, ale tworzy dłuższy kod.
|
UWAGA |
Chociaż tablicę można przekazać do podprogramu jako wartość, funkcje nie mogą zwracać tablic. |
|
WSKAZÓWKA |
Jeśli funkcja potrzebuje zwrócić informacje w postaci tablicy, tablica zwracana powinna zostać przekazana jako VAR (referencja) w liście parametrów. Wartości zwracane można następnie przypisać do funkcji. |
Proste wprowadzanie i wyprowadzanie danych
W X11-Basic istnieje wiele sposobów na pobieranie danych od użytkownika i przeglądanie innych danych. Można to zrobić za pomocą klawiatury, myszy, mikrofonu itp. Dane można wyświetlać na konsoli tekstowej, w oknie graficznym, odtwarzać na głośniku i tak dalej. Ponadto program X11-Basic może zapisywać i odczytywać pliki oraz tworzyć połączenia internetowe, Bluetooth lub USB.
Najprostszym wejściem i wyjściem do i od użytkownika jest konsola tekstowa, tak zwane standardowe wejście i standardowe wyjście. Odbywa się to w X11-Basic za pomocą podstawowych poleceń PRINT, INPUT i LINEINPUT. CLS powoduje wyczyszczenie ekranu.
Formatowanie wyjścia za pomocą polecenia PRINT USING
X11-BASIC generuje zwykle liczby w formie odpowiedniej do większości zastosowań. Czasami jednak wolisz bardziej szczegółową formę. Na przykład chcesz wyprowadzać dane finansowe z dwoma miejscami po przecinku poprawnie sformatowanymi. Lub chcesz wydrukować liczby w notacji naukowej. PRINT USING oferuje możliwości reprezentowania liczb w tej i prawie każdej innej formie.
|
UWAGA |
Istnieją również inne wbudowane polecenia do formatowania danych wyjściowych. X11-Basic oferuje tutaj, na przykład STR$(). Szczegółowe informacje na temat składni znajdują się w sekcjach dotyczących funkcji łańcuchowych. |
Ogólna składnia to:
PRINT <wyrażenie> USING "<ciąg znaków>"
„wyrażenie” powinno być liczbą. Łańcuch formatu określa sposób formatowania danych na ekranie. Łańcuch formatu może być zmienną łańcuchową, łańcuchem lub bardziej ogólnym wyrażeniem łańcuchowym.
Możesz również formatować łańcuchy za pomocą opcji PRINT USING. W tym przypadku jednak możliwości są ograniczone do wyprowadzania ciągu wyśrodkowanego, wyrównanego do prawej lub lewej
.
Funkcja USING$() działa prawie tak samo jak PRINT USING, ale tylko liczby mogą być sformatowane, nie łańcuchy. Wynik jest zwracany jako łańcuch, a nie jako wynik na ekranie.
W odróżnieniu od STR$(), gdzie możesz określić długość łańcucha, ilość cyfr znaczących liczby i flagi gdzie powinny znajdować się wiodące zera, USING() i PRINT USING używają klasycznego formatu w stylu BASIC do formatowania liczb.
Łańcuch formatu może zawierać dowolne litery, ale niektóre mają specjalne znaczenie. Wszystkie inne postacie są po prostu brane takimi, jakie są. Długość ciągu formatu określa długość pola wyjściowego. Cokolwiek jest sformatowane, zajmuje tyle miejsca, co znaki w ciągu formatu.
Najważniejszym znakiem specjalnym w łańcuchu formatującym jest symbol # reprezentujący miejsce cyfry wypełnione cyfrą liczby, która ma zostać sformatowana. Na przykład porównaj dane wyjściowe, które wynikają z dwóch podobnych instrukcji PRINT: pierwsza jest normalna, a druga używa funkcji USING.
x = | PRINT x | PRINT x USING "###" ----- + ------- + -------------------- 1 | 1 | 1 12 | 12 | 12 123 | 123 | 123 1234 | 1234 | *** -12 | -12 | -12
Bez USING, numer drukowany jest w lewo i zajmuje tylko tyle miejsca, ile potrzeba. Z USING łańcuch formatu "###" określa długość pola na dokładnie trzy znaki. W tym polu numer jest wyświetlany z wyrównaniem do prawej. Jeśli pole nie jest wystarczająco długie aby poprawnie przedstawić numer, zamiast tego zostaną wydrukowane gwiazdki. Jeśli potrzebujesz tylko drukować liczby całkowite w kolumnie z wyrównaniem do prawej, to ten przykład jest wystarczający. Zwróć uwagę, że liczba ujemna jest drukowana ze znakiem zajmującym jedno z pól liczbowych.
Podczas księgowania wpisów finansowych często stosuje się wyrównanie punktów dziesiętnych. Możesz również wydrukować dwa miejsca po przecinku, nawet jeśli są zerowe. Poniższy przykład pokazuje jak to zrobić. (Aby wydrukować liczby ujemne i mieć znak w ustalonej pozycji - ciąg znaków powinien zaczynać się od znaku minus).
x = | PRINT x USING "-##.##" ------ + ----------------------- 1 | 1:00 1.9 | 1.90 -3,14 |-3,14 1.238 | 1.24 123 | ****** 0 | 0:00 -123 | ******
Zauważ, że ten przykład zawsze drukuje dwie cyfry dziesiętne, nawet jeśli są zerami. Ponadto wynik jest najpierw zaokrąglany do dwóch miejsc po przecinku. Jeśli liczba jest ujemna, znak minus przyjmuje pozycję lidera lub pozycję wskazaną przez - lub + w ciągu formatującym. Jeśli liczba jest zbyt długa, aby można ją było wydrukować poprawnie (prawdopodobnie ze względu na znak minus), zamiast tego zostaną wydrukowane gwiazdki.
Kwoty pieniężne są często drukowane z wiodącym znakiem dolara ($) i przecinkami, które tworzą po lewej stronie przecinka trzycyfrowe grupy. Poniższy przykład pokazuje, jak to zrobić używając PRINT USING.
x = | PRINT x USING "$#,###,###.##" ----------- + ------------------------------ 0 | $ 0,00 1 | $ 1.00 1234 | $ 1,234.00 1234567.89 | $1,234,577.89 1e6 | $1,000,000.00 1e7 | 10,000,000.00 1e8 | *************
Znak dolara jest drukowany tylko wtedy, gdy nie potrzeba miejsca na cyfrę. Jest zawsze w tej samej pozycji (pierwszy) w polu. Przecinki oddzielające są drukowane tylko w razie potrzeby.
Jeśli
chcesz, aby znak dolara ($)
znalazł się bliżej numeru, a wszystkie spacje między znakiem dolara i
pierwszą cyfrą zniknęły, wykonaj następujące czynności:
x = | PRINT x USING "$$,$$$,$$#.##" ----------- + ---------------------------- 0 | $0.00 1 | $1,00 1234 | $ 1,234.00 1234567.89 | $1,234,567.89
Łańcuch formatu może również zezwalać na wyprowadzanie zer wiodących lub umieszczać gwiazdki (*) zamiast zera:
x = | PRINT x USING "$0,000,000.##" ----------- + ------------------------------ 0 | $0,000,000.00 1 | $0,000,001.00 1234 | $0,001,234.00 1234567.89 | $1,234,567.89 x = | PRINT x USING "$*,***,***. ##" ----------- + ------------------------------ 0 | $********0.00 1 | $********1.00 1234 | $****1,234.00 1234567.89 | $1,234,567.89 x = | PRINT x USING "* $$, $$$, $$ #. ##" ----------- + ------------------------------ 0 | *********$0.00 1 | *********$1.00 1234 | *****$1,234.00 1234567.89 | *$1,234,567.89
Ze względu na kompatybilność można użyć % w miejscu zer w ciągu formatującym, z jednym wyjątkiem: % nie może być pierwszym znakiem w ciągu formatu.
|
UWAGA |
Jeśli pierwszym znakiem jest % - ciąg formatu jest interpretowany jako ciąg formatu printf w stylu C (patrz poniżej). |
Można również formatować liczby za pomocą notacji naukowej. Ponieważ notacja naukowa składa się z dwóch części: części dziesiętnej i części wykładniczej, ciąg formatu musi również składać się z dwóch części. Część dziesiętna jest zgodna z zasadami już opisanymi. Część wykładnicza składa się z trzech do pięciu znaków (^), które powinny następować bezpośrednio po części dziesiętnej:
x = | PRINT x USING "+#.#####^^^^" ------------ + ----------------------------- 0 | +0.00000e+00 123,456 | +1.23456e+02 -.001324379 | -1.32438e-03 7e30 | +7.00000e+30 0,5e100 | +5.00000e+99 5e100 | ************
Przedrostek plus (+) w ciągu formatu gwarantuje, że znak liczby zostanie wydrukowany, nawet jeśli liczba jest dodatnia. Zauważ, że ostatniej liczby nie można sformatować, ponieważ część wykładnicza wynosi 100, co wymaga pola wykładniczego z pięcioma daszkami. Zwróć także uwagę, że zera wiodące są wstawiane jeśli jest więcej niż potrzeba pozycji dla wykładnika. Na koniec zwróć uwagę, że końcowe zera są drukowane w części dziesiętnej.
Oprócz zasad formatowania opisanych powyżej X11-Basic udostępnia inny, alternatywny ciąg formatów. Jeśli pierwszym znakiem ciągu formatu jest %, ciąg formatu traktowany jest jako styl C, tak zwany formater printf.
Oto kilka przykładów:
x = | format $ = | PRINT x USING format $ ------------ + ------------------------------------ 0 | "%012g" | 000000000000 123456 | "%.1g" | 1e+02 -.001624 | "%.1g" | -0.002
Te ciągi formatowania są zgodne ze standardem języka C.
Łańcuchy mogą być również sformatowane za pomocą funkcji PRINT USING, ale nie za pomocą USING$(), chociaż mamy mniej opcji dla ciągów niż dla liczb. W sformatowanym polu napisy mogą być drukowane w postaci wyrównanej do lewej, wyśrodkowanej lub do prawej. Podobnie jak w przypadku liczb, jeśli ciąg jest zbyt długi, aby się zmieścić, drukowane są gwiazdki.
Poniższe przykłady powinny to wyjaśnić:
PRINT "|";"OK" USING "#####";"|" ! Wynik: | OK | PRINT "|";"OK" USING ">####";"|" ! Wynik: | OK| PRINT "|";"Hello" USING ">####";"|" ! Wynik: |Hello| PRINT "|";"Goodby" USING ">####";"|" ! Wynik: |*****|
Jeśli centrowanie nie może być dokładne, dodatkowe miejsce zostanie umieszczone po prawej stronie.
Właściwie każdy ciąg może być użyty jako ciąg formatujący. Tylko długość ciągu określa długość pola wyjściowego. Ważny jest tylko pierwszy znak ciągu formatu.< powoduje wyrównanie do lewej, > do prawej, a wyśrodkowanie w każdym innym przypadku. Jest to szczególnie przydatne przy drukowaniu nagłówków dla tabeli numerycznej. Poniższy przykład pokazuje, w jaki sposób można sformatować nagłówek z tym samym łańcuchem formatu, którego używaliśmy wcześniej dla liczb:
s$ = | PRINT s$ USING "$#,###,###.##" ----------------------- + -------------------------- ----- "Gotówka" | Gotówka "Zobowiązania" | Zobowiązania "Rozrachunki z odbior." | *************
Kontrola przebiegu programu – pętle i warunki
W X11-Basic występuje standardowa pętla FOR-NEXT:
FOR i%=1 TO 5
PRINT i%
NEXT i%
Ten niewielki przykładowy program wykonuje 5 razy instrukcję PRINT i% - zlicza zmienną i% od 1 do 5 i wyświetla bieżącą wartość na ekranie.
Instrukcję TO można zastąpić przez DOWNTO powodując zmniejszanie wartości zmiennej, dodanie STEP x spowoduje zmiany wartości zmiennej o x.
Pętlę FOR-NEXT można warunkowo zakończyć stosując polecenie EXIT IF.
Instrukcję warunkową IF stosujemy w następujący sposób:
FOR i% = 1 do 10 IF i% = 5 PRINT "i% = 5" ELSE PRINT "i% <> 5" ENDIF NEXT i%
Ten program dla każdej iteracji pętli sprawdza, czy i% w linii IF wynosi 5. Jeśli ten warunek jest spełniony interpreter wykonuje gałąź programu aż do ELSE i pomija następną część. Jeśli warunek nie jest spełniony X11-Basic wykonuje tylko część po ELSE. Upewnij się, że każdy IF kończy się ENDIF, w przeciwnym razie X11-Basic wygeneruje komunikat o błędzie. Możesz również pominąć część ELSE, wtedy X11-Basic nie zrobi niczego, jeśli warunek nie będzie spełniony.
Poniższa pętla warunkowa jest wykonywana, dopóki warunek nie zostanie spełniony:
REPEAT ... UNTIL <warunek>
Jest to tak zwana pętla REPEAT-UNTIL. Jest uruchamiana co najmniej raz, a X11-Basic sprawdzi warunek dopiero po wykonaniu zawartości pętli. Dopóki warunek jest fałszywy, pętla jest powtarzana.
Czasem konieczne jest sprawdzenie warunku przed wejściem do pętli. W tym celu najlepsza jest następująca konstrukcja:
WHILE <warunek> ... WEND
To jest tak zwana pętla WHILE-WEND. Tutaj warunek jest już sprawdzany na początku pętli, a pętla jest wykonywana tylko gdy warunek jest spełniony (true).
X11-Basic ma też specjalną konstrukcję pętli nieskończonej, chociaż możesz z łatwością tworzyć niekończące się pętle za pomocą powyższych typów, jeśli użyjesz warunku, który nigdy się nie spełni. Niekończąca się pętla nazywa się pętlą DO. Te 3 pętle w przykładzie mają taką samą funkcjonalność i są powtarzane bez końca.:
DOPRINT "bez końca"LOOPi%=0REPEATPRINT "bez końca"UNTIL i%=1i%=0WHILE i%=0PRINT "bez końca"WEND
W tym momencie powinieneś wiedzieć, że możesz zatrzymać lub anulować swój program X11 Basic w dowolnym momencie. Jest to konieczne, jeśli twój program utknie w nieskończonej pętli, która nie była przewidziana. Naciśnij CONTROL-c, a X11-Basic zatrzyma program. Ponowne CONTROL-c powoduje wyjście
.
Czasami chcesz zakończyć działającą pętlę w punkcie innym niż oficjalny początek pętli lub koniec pętli. Użyj instrukcji EXIT IF w swojej pętli, aby uzyskać dodatkowe warunki. To także kończy pętle FOR-NEXT, jeśli chcesz, i jest to jedyny sposób na wyjście z pętli DO-LOOP:
i% = 1 DO PRINT "i% ="; i% EXIT IF I% = 5 i% = i + 1% LOOP
EXIT IF przerywa pętlę, gdy warunek ma wartość true, i kontynuuje program po zakończeniu pętli.
Diagnostyka błędów w czasie wykonywania
Niektóre błędy mogą zostać przechwycone przez program użytkownika za pomocą komendy ON ERROR GOTO lub ON ERROR GOSUB. Jeśli nie została określona procedura pułapek błędów, wykonywanie programu jest przerywane, a komunikat jest wysyłany z odpowiednim numerem linii. Komunikaty o błędach są ustandaryzowane. Każdy komunikat o błędzie ma odpowiedni numer, który jest również przechowywany w zmiennej systemowej ERR i może być uwzględniony w procedurze wychwytywania błędów. Lista standardowych komunikatów o błędach według numerów znajduje się w rozdziale {błędy}.
Całą dostępną pamięć programu można adresować za pomocą PEEK/POKE, LPEEK/LPOKE, DPEEK/DPOKE, itp.
Ostrożnie ! Możesz manipulować wszystkimi symbolami interpretera i dynamicznie połączonych bibliotek oraz twoim programem. Przestrzenie adresów powiązane z innymi programami, które nie są blokami pamięci współużytkowanej nie mogą być adresowane. Próba zrobienia tego spowoduje błąd segmentacji.
Okno graficzne otwiera się automatycznie, gdy pierwsze polecenie graficzne pojawi się w twoim programie. Bez poleceń graficznych nie jest potrzebny serwer X11, a programy działają również w konsoli tekstowej lub jako demon lub jako skrypty CGI. Ale jeśli chcesz coś narysować, na przykład stosując LINE, CIRCLE albo BOX, kontrolować wskaźnik myszy lub klawiatury, lub w korzystać z graficznego interfejsu użytkownika za pomocą, na przykład, ALERT albo MENU, wówczas otworzy się okno grafiki o rozmiarze domyślnym 640x400 pikseli. Wszystkie wydruki graficzne można wykonać w pełnym kolorze, który można ustawić za pomocą instrukcji GET_COLOR() i COLOR. Ponadto można otworzyć jednocześnie do 16 różnych okien graficznych. Zwróć uwagę, że wszystkie grafiki są wyświetlane tylko po komendzie `SHOWPAGE '. Pozwala to na szybkie animacje.
Aby włączyć animowaną grafikę bitmapową i symbole, X11-Basic udostępnia komendy GET i PUT, które umieszczają prostokątne obszary okna graficznego w zmiennej łańcuchowej, lub bitmapowe dane graficzne z łańcucha na ekranie graficznym lub oknie. Używany format pliku jest standardową bitmapą BMP, więc można również ładować i wykorzystywać zewnętrznie utworzone ikony z innych plików. Obsługiwane są przezroczystość i kanały alfa.
Odczytywanie i zapisywanie danych z plików
Zanim odczytasz plik lub zapiszesz do pliku, musisz go otworzyć (OPEN). Gdy skończysz, powinieneś zamknąć go ponownie (CLOSE). Każdy otwarty plik jest identyfikowany prostym numerem, który może być przechowywany w zmiennej i używany z poleceniami PRINT i INPUT, jeśli chcesz uzyskać dostęp do pliku. Jeśli potrzebujesz większej kontroli, możesz użyć poleceń uniwersalnych INP() i OUT do odczytu i zapisu pojedynczego bajtu lub od razu odczytać cały plik jako blok binarny używając BLOAD.
Połączenia internetowe i Bluetooth, specjalne pliki i gniazda
X11-Basic umożliwia podłączenie programu z innym programem na innym (lub tym samym) komputerze-hoście za pośrednictwem standardowych protokołów i potoków Internetowych lub Bluetooth.
Istnieją dwa typy połączeń z innymi komputerami w sieci: połączenie strumieniowe (jak TCP / IP dla połączeń internetowych) oraz bezpołączeniowa, niepewna usługa pakietów datagramowych (UDP dla połączeń internetowych i np L2CAP dla Bluetooth).
Inny sposób przesyłania danych między dwiema aplikacjami na tym samym komputerze nazywa się potokami. Potoki to specjalne pliki tworzone w lokalnym systemie plików.
Lokalna komunikacja między procesami: potoki
Potok jest jednokierunkowym kanałem danych, który może być używany do komunikacji międzyprocesowej. Jądro UNIX zwykle obsługuje ten mechanizm. Potok może być używany do wysyłania informacji lub danych z jednego procesu do drugiego.
Oto mały przykładowy program:
PIPE #1,#2a=FORK()IF a=0 ! Instancja podrzędnaGPRINT "Hallo, jestem dzieckiem !",bDOSHOWPAGELINEINPUT #1,t$GPRINT t$LOOP' Ta instancja nigdy się nie kończy...ELSE IF a=-1PRINT "ERROR, fork() failed !"QUITELSE ! Instancja nadrzędnaDODUMPALERT 1,"Hi, jestem rodzicem. Child PID="+str$(a),1," OK | Kill Child ! ",bDUMPPRINt #2,SYSTEM$("date")FLUSH #2IF b=2SYSTEM "kill "+str$(a)ALERT 1,"Child PID="+str$(a)+" killed !",1," OK ",bQUITENDIFLOOPENDIFQUIT
Zamiast korzystania z potoków komunikacja między procesami może również odbywać się za pośrednictwem segmentu pamięci współdzielonej. X11-Basic obsługuje również polecenia do tworzenia i dostępu do takich segmentów pamięci współużytkowanej.
Ogólnodostępna komunikacja: gniazda
Większość komunikacji między procesami wykorzystuje model klient-serwer. Terminy te odnoszą się do dwóch procesów, które komunikują się z sobą. Jeden z dwóch procesów - klient, łączy się z innym procesem - serwerem, zwykle w celu wysłania żądania informacji. Dobrą analogią jest osoba dzwoniąca do innej osoby.
Należy zauważyć, że klient musi wiedzieć o istnieniu i adresie serwera, ale serwer nie musi znać adresu klienta (ani nawet istnienia) przed nawiązaniem połączenia. Należy również pamiętać, że po nawiązaniu połączenia obie strony mogą wysyłać i odbierać informacje.
Po utworzeniu gniazda program musi określić domenę adresową i typ gniazda. Dwa procesy mogą komunikować się ze sobą tylko wtedy, gdy ich gniazda są tego samego typu i znajdują się w tej samej domenie. Istnieją dwie wspólne domeny adresowe, (lokalna) domena Unix, w której komunikują się dwa procesy udostępniające wspólny system plików, oraz domena internetowa, w której dwa procesy komunikują się na dowolnych dwóch hostach w Internecie. Każdy z nich ma swój własny format adresu. Inną domeną, o której można wspomnieć, jest domena Bluetooth dla łączy radiowych krótkiego zasięgu. Działa podobnie jak połączenia internetowe, ale korzysta z własnej przestrzeni adresowej.
Adres gniazda w domenie uniksowej jest łańcuchem, który jest w zasadzie wpisem w systemie plików. Można go wywoływać stamtąd jak plik. X11 Basic może używać wszystkich typowych poleceń wprowadzania i wyprowadzania plików.
Adres gniazda w domenie internetowej składa się z adresu internetowego hosta (każdy komputer w Internecie ma unikalny adres 32-bitowy, często nazywany adresem IP (lub identyfikatorem Bluetooth). Ponadto każde gniazdo wymaga numeru portu na tym hoście. Numery portów to 16-bitowe liczby całkowite bez znaku. Niższe numery są zarezerwowane w Internecie dla standardowych usług. Na przykład numer portu dla serwera FTP wynosi 21. Ważne jest, aby domyślne usługi były na tym samym porcie na wszystkich komputerach, aby klienci mogli znać ich adresy. Jednak numery portów powyżej 2000 są zwykle swobodnie dostępne.
Rodzaje gniazd:
Istnieją dwa popularne typy gniazd, gniazda strumieniowe i gniazda datagramowe. Gniazda strumieniowe obsługują komunikację jako ciągły strumień znaków, a gniazda datagramowe wysyłają i odbierają całe wiadomości lub bloki na raz. Każdy typ gniazda wykorzystuje własny protokół komunikacyjny. Gniazda strumieniowe do połączeń internetowych używają protokołu TCP (Transmission Control Protocol). Jest to niezawodny, ukierunkowany na strumień protokół. Gniazda Datagram używają UDP (Unix Datagram Protocol), który jest niepewny i zorientowany na wiadomości. Niepewność oznacza tutaj, że nie ma żadnej gwarancji, że pakiet danych dotrze do odbiorcy lub, że kilka pakietów dotrze w prawidłowej kolejności.
To samo dotyczy połączeń Bluetooth, gniazda strumieniowe korzystają z tak zwanego protokołu RFCOMM, a gniazda datagramowe korzystają z protokołu L2CAP.
Gniazda w X11-Basic można utworzyć za pomocą polecenia OPEN.
TCP / IP:
Protokół TCP (Transmission Control Protocol) zapewnia niezawodną usługę przesyłania strumienia bajtowego między dwoma punktami końcowymi w sieci komputerowej. TCP korzysta z adresu IP do wysyłania pakietów za pośrednictwem sieci. IP jest z natury zawodne, więc protokół TCP chroni przed utratą danych, uszkodzeniem danych, pomieszaniem pakietów i duplikowaniem danych przez dodawanie sum kontrolnych i numerów sekwencji do przesyłanych danych. Po stronie odbiorczej przychodzące pakiety są potwierdzane i ewentualnie ponownie żądane, jeśli pakiety danych nie dotarły.
Przed wysłaniem danych przez sieć protokół TCP nawiązuje połączenie z miejscem docelowym, wymieniając pakiety zarządzania. Połączenie zostanie przerwane w ten sam sposób, jeśli nie ma już być przesyłanych więcej danych.
TCP ma wielopoziomowy mechanizm kontroli przepływu, który stale dostosowuje szybkość transmisji przetwornika w celu maksymalizacji przepustowości danych, unikając przeciążenia i utraty pakietów w sieci. Próbuje także w pełni wykorzystać zasoby sieciowe, pakując jak najwięcej danych do jednego pakietu IP.
Wywołania systemowe do łączenia są nieco inne dla klienta i serwera, ale oba zawierają podstawową konstrukcję gniazda. Gniazdo to jeden koniec kanału komunikacji międzyprocesowej. Obydwa procesy budują własne gniazdo.
Kroki konfigurowania gniazda po stronie klienta są następujące:
1. Utwórz gniazdo za pomocą polecenia OPEN udostępniającego numer portu
OPEN "US", #1, "client", 5000
2. Połącz gniazdo z adresem serwera poleceniem CONNECT
CONNECT #1, "ptbtime1.ptb.de", 13
Zamiast używać kroków 1 i 2, możesz alternatywnie użyć komendy połączonej:
OPEN "UC", #2, "ptbtime1.ptb.de", 13
3. Wysyłaj i odbieraj dane. Istnieje kilka sposobów, aby to zrobić, ale najprostszym sposobem jest użycie poleceń PRINT, SEND, WRITE, READ, RECEIVE i INPUT.
PRINT #2, "GET / index.html" FLUSH #2 WHILE INP?(#2) LINEINPUT #2, t$ PRINT "got:"; t$ WEND
4. Zamknij połączenie za pomocą:
CLOSE #1
Kroki w celu skonfigurowania gniazda po stronie serwera są następujące:
1. Utwórz gniazdo za pomocą polecenia OPEN i połącz gniazdo z numerem portu na komputerze hosta.
OPEN "US", #1, "server", 5000
2. Posłuchaj połączeń przychodzących i
3. zaakceptuj połączenie z jeszcze jednym OPEN. Otwiera się połączenie z klientem:
OPEN "UA", #2, "", 1
To połączenie blokuje się, dopóki klient nie połączy się z serwerem.
4. Wysyłaj i odbieraj dane o zaakceptowanym połączeniu:
PRINT #2,"X11-Basic Test-server ..."FLUSH #2DOIF INP?(#2)LINEINPUT #2,t$PRINT "got: ";t$ENDIFEXIT IF t$="quit"LOOPPRINT #2,"Do widzenia..."FLUSH #2
5. Zamknij nawiązane połączenie:
CLOSE #2
i czekać na następne połączenie (krok 3) lub
6. Zamknij gniazdo, jeśli już go nie potrzebujesz.
CLOSE #1
UDP:
Protokół UDP (User Datagram Protocol) zapewnia niepewną pakietową usługę przesyłania danych między punktami końcowymi w sieci.
Najpierw za pomocą polecenia OPEN należy utworzyć gniazdo:
OPEN "UU", nr 1, "sender", 5556
Po utworzeniu gniazda UDP jego adresy lokalne i zdalne nie są określone. Datagramy można wysyłać natychmiast, podając w SEND poprawny adres docelowy (131.195.15.200) i port (5000) jako argument:
SEND #1,"To jest moja wiadomość", CVL(CHR$(131)+CHR$(195)+CHR$(15)+CHR$(200)),5000
UDP używa formatu adresu IPv4, więc 32-bitowa liczba całkowita musi zostać przekazana. Zostało to wykonane w powyższym przykładzie za pomocą funkcji CVL().
Gdy wywoływany jest CONNECT dla gniazda, ustawiany jest domyślny adres docelowy i można, używając SEND, wysyłać datagramy bez podawania adresu docelowego. Możliwe jest również wysyłanie do innych miejsc docelowych podając adres w SEND.
CONNECT #1, "localhost", 5555 SEND #1, "To jest moja wiadomość"
Wszystkie operacje odbioru zwracają tylko jeden pakiet na raz.
IF INP?(#1) RECIVE #1, t$, adr PRINT "Received Message:"; t$; "from"; HEX$(adr) ENDIF
INP?(#n) zwraca rozmiar następnego oczekującego datagramu w bajtach lub 0, jeśli nie ma oczekującego datagramu.
Gniazdo powinno być zamknięte, gdy połączenie nie jest już używane:
CLOSE #1
UDP nie gwarantuje, że dane rzeczywiście docierają do miejsca przeznaczenia, ani nie gwarantuje, że pakiety danych docierają w kolejności, w jakiej zostały wysłane przez źródło, ani nie gwarantuje, że przybywa tylko jedna kopia danych. Jednak UDP gwarantuje integralność danych przez dodanie sumy kontrolnej do danych przed transmisją.
Nawiązanie połączenia między dwoma urządzeniami za pomocą adaptera Bluetooth jest podobne do połączenia internetowego. Podobnie można użyć połączenia strumieniowego (za pomocą RFCOMM) lub połączenia opartego na rekordach (przy użyciu L2CAP).
Polecenia X11 Basic są również podobne. Jedyną zauważalną różnicą jest to, że zamiast używać adresu IP, należy użyć identyfikatora Bluetooth i nie ma systemu nazw domen, który mógłby przetłumaczyć nazwę urządzenia na identyfikator.
Oznacza to, że jeśli chcesz połączyć się z urządzeniem Bluetooth, najpierw musisz znać jego ID. Identyfikator składa się z sześciu bajtów (zamiast czterech w przypadku adresu internetowego IPV4). Zwykle są zapisywane jako ciąg znaków w formacie: hh:hh:hh:hh:hh:hh ze wszystkimi 6 bajtami w dwucyfrowych wartościach szesnastkowych oddzielonych dwukropkami, np: 78:F5:FD:15:4A:3A.
Możesz albo zakodować identyfikator w swoim programie, albo wyszukać widoczne urządzenia Bluetooth.
Skanowanie można wykonać w X11-Basic funkcjami FSFIRST$() i FSNEXT$():
a$=FSFIRST$("","*","b")WHILE LEN(a$)PRINT a$PRINT "Adress: ";WORD$(a$,1)PRINT "Name: ";WORD$(a$,2)adr$=WORD$(a$,1)a$=FSNEXT$()WEND
RFCOMM (Radio Frequency Communication) zapewnia użytkownikowi proste, niezawodne połączenie transmisji danych podobne do TCP.
Wiele aplikacji Bluetooth korzysta z RFCOMM, ponieważ jest szeroko stosowany i obsługiwany przez wiele swobodnie dostępnych interfejsów programistycznych w większości systemów operacyjnych. Ponadto aplikacje korzystające z portu szeregowego do komunikacji mogą być szybko przeniesione do RFCOMM.
Podobnie jak w przypadku TCP / IP podstawową konstrukcją jest gniazdo do nawiązywania połączenia za pośrednictwem RFCOMM. Dwa procesy (serwer i klient) tworzą własne gniazdo.
Kroki w celu skonfigurowania gniazda po stronie klienta są następujące (zakładając, że identyfikator Bluetooth, z którym chcesz się połączyć, jest zawarty w adr$):
1. Utwórz gniazdo za pomocą polecenia OPEN określającego numer portu
2. Połącz gniazdo z adresem serwera za pomocą polecenia CONNECT
Zamiast używać kroków 1 i 2, możesz alternatywnie użyć komendy połączonej, analogicznie jak w połączeniu TCP/IP.
3. Wysyłaj i odbieraj dane. Istnieje kilka sposobów, aby to zrobić, ale najprostszym sposobem jest użycie poleceń PRINT, SEND, WRITE, READ, RECEIVE i INPUT:
PRINT #2, "Cześć" FLUSH #2 WHILE INP?(#2) LINEINPUT #2, t$ PRINT "got: "; t$ WEND
4. Zamknij połączenie za pomocą:
CLOSE #1
Kroki w celu skonfigurowania gniazda po stronie serwera są następujące:
1. Utwórz gniazdo za pomocą polecenia OPEN i połącz gniazdo z numerem portu na komputerze-hoście.
2. Posłuchaj połączeń przychodzących i
3. zaakceptuj połączenie jeszcze jednym poleceniem OPEN. Otwiera się połączenie z klientem:
OPEN "UA", #2, "", 1
To połączenie blokuje się, dopóki klient nie połączy się z serwerem.
4. Wysyłaj i odbieraj dane o zaakceptowanym połączeniu:
PRINT #2,"X11-Basic Test-server ..."FLUSH #2DOIF INP?(#2)LINEINPUT #2,t$PRINT "got: ";t$ENDIFEXIT IF t$="quit"LOOPPRINT #2,"Do widzenia..."FLUSH #2
5. Zamknij nawiązane połączenie:
CLOSE #2
i czekać na następne połączenie (krok 3) lub
6. Zamknij gniazdo, jeśli już go nie potrzebujesz.
CLOSE #1
L2CAP
(L2CAP = Logical link control and adaptation protocol)
Najpierw za pomocą polecenia OPEN należy utworzyć gniazdo:
Po utworzeniu gniazda L2CAP jego adresy lokalne i zdalne nie są określone. Datagramy można natychmiast wysłać używając SEND z poprawnym adresem docelowym i portem jako argumentem:
Używamy formatu adresu IPv4, więc należy podać długą liczbę całkowitą.
Gdy wywoływany jest CONNECT dla gniazda, ustawiany jest domyślny adres docelowy i można wysyłać datagramy używając SEND bez podawania adresu docelowego.
Wszystkie operacje odbioru zwracają tylko jeden pakiet.
INP?(#n) zwraca rozmiar następnego oczekującego datagramu w bajtach lub 0, jeśli nie ma oczekujących datagramów.
Gniazdo powinno być zamknięte, gdy połączenie nie jest już używane:
CLOSE #1
Maksymalny rozmiar pakietu nie powinien przekraczać 672 bajtów.
Obsługa Bluetooth w X11-Basic jest w trakcie wdrażania i nie działa jeszcze w systemach Android i WINDOWS.
X11-Basic ma wbudowany interfejs programowania USB, który pozwala programom X11 Basic na dostęp do urządzeń USB podłączonych do komputera. Interfejs jest na poziomie prawie sprzętowym, więc sterownik dla konkretnego podłączonego sprzętu musi być napisany w X11-Basic. Dzięki tym metodom łatwo można używać rejestratorów danych i adapterów USB do RS232. Zasadniczo dostęp do dowolnego urządzenia USB można uzyskać, jeśli znany jest protokół przesyłania danych i interpretacji danych.
Pakiet X11-Basic zawiera przykładowy program usb-VDL101T.bas odczytujący dane z rejestratora VOLTCRAFT VDL101-T.
Obsługa USB jest w toku i może jeszcze nie działać na systemach Android i WINDOWS.
Urządzenia USB są otwierane za pomocą polecenia OPEN. Zamiast nazwy pliku używana jest kombinacja PID / VID. Ponadto do ubsługi urządzenia stosowane są CLOSE, IOCTL(), SEND i RECEIVE. (PRINT i INPUT niestety aktualnie nie działają).
Dane w kodzie źródłowym programu
Stosowane są typowe dla języka Basic instrukcje READ, DATA, RESTORE. Ponadto dostępna jest funkcja INLINE$(), za pomocą której można przechowywać duże binarne segmenty danych w kodzie źródłowym. Te ostatnie są odpowiednio zakodowane wcześniej.
Poniższy przykład pokazuje, jak przechowywać dowolne dane binarne, np. bitmapy.
' output of inline.bas for X11-Basic 23.04.2002' demo 104 Bytes.demo$=""demo$=demo$+"5*II@V%M@[4D=*9V,)5I@[4D=*9V,(IR?*IR=6Y*A:]OA*IS?F\.&IAI?J\D8ZII"demo$=demo$+",*5M=;1I@V%P=;1I?F%OaJ]R=:\P,*5E?J\D>*)X,*9W,*AI>ZUE@+%X/F\R&JAV"demo$=demo$+"A;1W&HXR&DL$"a$=INLINE$(demo$)PRINT len(a$),a$' show a bitmapbiene$="($$43$%*<(1G,=E5Z&MD%_DVW'b*%H-^,EQ6>VTL$$$$"CLEARWt$=INLINE$(biene$)COLOR COLOR_RGB(1,1,1)FOR i=0 TO 40PUT_BITMAP t$,i*16,0,16,16NEXT i
Program inline.bas dostarczany jest z X11-Basic. Konwertuje on i kompresuje każdy plik binarny do gotowego do użycia kodu źródłowego X11-Basic.
Biblioteka dołączana dynamicznie (.so=shared object) to zbiór funkcji (podprogramów), które mogą być używane przez programy lub inne biblioteki. Funkcja z biblioteki dynamicznej musi być wywoływana bezpośrednio lub pośrednio przez działającą aplikację i nie może być uruchamiana jako samodzielny program.
Biblioteki Dynamic Link oszczędzają miejsce, ponieważ wiele aplikacji może jednocześnie korzystać z pojedynczego pliku obiektu współdzielonego, który wystarczy załadować do pamięci tylko jeden raz. Inną zaletą posiadania osobnych i dodawalnych do runtime funkcji w bibliotece dynamicznej jest to, że można je modyfikować oddzielnie i niezależnie od aplikacji, w której będą później używane, o ile argumenty i wartości zwracane przez funkcję nie ulegną zmianie. Wadą w korzystaniu z .so jest to, że aplikacja zależy od istnienia oddzielnego modułu. Jeśli plik .so nie zostanie znaleziony, aplikacja zostanie zamknięta.
Wszystkie udokumentowane funkcje z udostępnionych obiektów innych pakietów oprogramowania mogą być używane i wywoływane w programie X11 Basic.
Jednak X11-Basic nie sprawdza liczby i rodzaju parametrów funkcji, a Ty jesteś odpowiedzialny za ich przesłanie we właściwym formacie i kolejności.
Użycie funkcji C w bibliotekach współdzielonych
Jeśli chcesz używać własnych funkcji napisanych w innym języku programowania (np. C) w X11-Basic, musisz najpierw skompilować je do biblioteki dynamicznej. Spowoduje to utworzenie pliku .so lub .dll.
Zanim aplikacja X11 Basic będzie mogła korzystać z funkcji jednego z nich, musi zostać załadowana biblioteka dynamiczna .so. Robi się to poleceniem LINK.
LINK # 1, "myfile.so"
Biblioteka zostanie połączona w czasie wykonywania.
Na przykład, jeśli chcesz wywołać funkcję C binit() z biblioteki `track.so`, możesz to zrobić za pomocą następujących linii kodu:
IF NOT EXIST("./trackit.so")SYSTEM "gcc -O3 -shared -o trackit.so trackit.c"ENDIFLINK #11,"./trackit.so"~CALL(SYM_ADR(#11,"binit"),L:n,L:200,P:VARPTR(x(0)),P:VARPTR(bins(0)))
W celu wyjaśnienia poniżej kod źródłowy C dla wspomnianej funkcji:
trackit.c
#include <stdlib.h>#include <stdio.h>#include <math.h>void binit(int n,int dn,double *x,double *data) {int i,j;int over=0,under=0;for(i=0;i<n;i++) {j=(int)((x[i]+PI)/2/PI*dn);if(j<0) under++;else if(j>=dn) over++;else data[j]++;}}
Aplikacje mogą jednocześnie ładować do 99 plików obiektów współdzielonych, chociaż zakres numerów kanałów jest również używany do otwierania plików.
X11-Basic zarządza wewnętrzną tabelą z 99 wpisami do przechowywania wewnętrznego odniesienia załadowanych plików. Odnośniki te są niezbędne do uzyskania dostępu do danych.
Pliki .so są usuwane z pamięci za pomocą polecenia UNLINK:
UNLINK #11
Funkcja CALL() zezwala tylko na typ integer (int) dla zwracanej wartości. Aby uzyskać wartość zwracaną w postaci zmiennoprzecinkowej, użyj zamiast niej CALLD(). Jeśli wywoływana funkcja zwraca skomplikowaną strukturę danych, użyj zamiast niej CALL$().
|
WSKAZÓWKA |
Obecnie istnieje ograniczenie w zastosowaniu CALL(), CALLD() i CALL$() w 64-bitowych systemach operacyjnych. Tutaj tylko parametry całkowite i wskaźnikowe są poprawnie przekazywane do wywoływanej funkcji. Jeśli sam napisałeś funkcję biblioteki, możesz obejść to ograniczenie, przekazując zamiast tego wskaźnik do zmiennej zmiennoprzecinkowej (double *). |
|
UWAGA |
Mechanizm wywołania zależy od interfejsu programowania (ABI), który jest inny dla różnych platform. Niestety interfejs AMD86x64 jest już tak skomplikowany, że nie ma bezpośredniego przenośnego sposobu na jego pełne wdrożenie. Jest nadzieja, że w przyszłości będzie można korzystać z biblioteki zewnętrznej, która oferuje przenośny sposób. Dobrym kandydatem będzie biblioteka interfejsu funkcji obcych libffi. |
Możliwe są następujące typy parametrów:
|
D: |
64-bit float (double) |
|
L: |
32-bit integer (int) (%) |
|
W: |
16-bit signed (short) |
|
B: |
8-bits signed (char) |
|
F: |
4 byte float (float) |
|
R: |
8 byte long integer (long long) |
|
P: |
4 or 8 byte pointer (void *) |
Opcja P: zachowuje się w taki sam sposób, jak L: w 32-bitowych systemach operacyjnych. Ale należy użyć P: dla wskaźników VARPTR() w pamięci, aby można je było przetworzyć z 32-bitowej reprezentacji X11 Basic na 64-bitowe adresy w 64-bitowych systemach operacyjnych. Opcje B: i W: zachowują się podobne do opcji L:.
Funkcja SYM_ADR() określa adres funkcji według jej nazwy. Pisownia nazwy funkcji musi więc być dokładnie taka sama, jak pisownia funkcji w .so.
Jeśli podajesz adres w łańcuchu, na końcu musisz dodać bajt zerowy.
Zwykle X11-Basic zajmuje się zarządzaniem pamięcią dla programisty. Kiedy deklarowana jest zmienna, łańcuch lub tablica, X11-Basic przydziela wymaganą pamięć i uwalnia ją po zamknięciu aplikacji. Mogą jednak wystąpić sytuacje, w których programista chce zarezerwować dodatkową pamięć.
Jeśli aplikacja musi przechowywać niewielką ilość danych, do jej przechowywania należy użyć łańcuchów. Ciągi są często używane jako bufory danych dla funkcji. Adres pamięci zajmowanej przez ciąg można uzyskać za pomocą funkcji VARPTR(). Jego długość dzięki funkcji LEN(). Łańcuchy mogą mieć rozmiar 2 gigabajtów i mogą przechowywać dowolne bajty. Wystarczająco dużo dla wielu aplikacji. Jednak adres łańcucha może się zmienić po każdym przypisaniu danych. Powinieneś to rozważyć.
Aby zarezerwować pamięć z globalnej i systemowej puli pamięci użytkownika programu, możesz użyć funkcji MALLOC(). Na przykład, aby zarezerwować 2000 bajtów, możesz napisać:
ptr%=MALLOC(2000)
Adres początku obszaru pamięci znajduje się w ptr%. W przeciwieństwie do ciągów zarezerwowany obszar pamięci pozostaje zawsze w tym samym miejscu, więc jego adres nie ulega zmianie.
Globalny blok pamięci, który został zarezerwowany przez MALLOC(), musi zostać zwolniony za pomocą funkcji FREE(). Aplikacja powinna zawsze zwolnić wszystkie bloki pamięci przed wyjściem.
Na przykład:
FREE ptr%
Przydzielona pamięć przez MALLOC() może być dostępna tylko dla jednego procesu. Jeśli dwie różne instancje X11 Basic lub ogólnie dwa różne uruchomione programy X11 Basic chcą uzyskać dostęp do tej samej pamięci (na przykład w celu współużytkowania lub wymiany danych), muszą zamiast tego używać pamięci współużytkowanej (współdzielonej).
Segment pamięci dzielonej musi najpierw zostać utworzony i przypisany. Powinno to zostać wykonane tylko przez jeden z programów. Twórca wybiera również klucz (który jest tylko liczbą całkowitą), który musi być używany przez wszystkie inne programy, które chcą później uzyskać dostęp do tej pamięci. Jako przykład wybieramy klucz 4711. Aby przypisać 2000 bajtów, można napisać:
id=SHM_MALLOC(2000,4711)
W przeciwieństwie do MALLOC(), SHM_MALLOC() nie zwraca bezpośrednio adresu. Zamiast tego zapewnia identyfikator wspólnego segmentu pamięci powiązanego z kluczem. Identyfikator jest tylko liczbą całkowitą. Nowy segment pamięci współdzielonej jest tworzony, jeśli nie ma jeszcze segmentu pamięci współdzielonej odpowiadającego kluczowi, w przeciwnym razie używany jest już istniejący.
Aby uzyskać adres, który możesz następnie użyć tak normalnie jak wszystkie inne adresy pamięci, musisz wypróbować funkcję SHM_ATTACH():
adr%=SHM_ATTACH(id)
Gdy drugi proces zna klucz i rozmiar segmentu pamięci współdzielonej (lub przynajmniej jego identyfikator), może również dołączyć ten sam segment do swojej przestrzeni adresowej. W efekcie dostanie inny adres (adr%), ale zapisanie w pamięci i odczytanie z niej będzie miało teraz wpływ na wszystkie inne procesy używające tego wspólnego segmentu.
Kiedy nie jest już używany, segment powinien być oddzielony od przestrzeni adresowej każdego z procesów, które go używały (aby adr% nie mógł być już używany). Jeśli segment pamięci współdzielonej powinien zostać całkowicie usunięty z pamięci (a cała jego zawartość powinna zostać usunięta), twórca tego segmentu może go zwolnić za pomocą SHM_FREE.
SHM_DETACH adr% SHM_FREE id
Jeśli nie zostanie zwolniony, pozostanie w pamięci komputera, dopóki ten nie zostanie wyłączony lub zrestartowany.
- Programy X11-Basic mogą uruchamiać inne programy za pomocą poleceń SYSTEM i SYSTEM$().
- Funkcja ENV$() zapewnia dostęp do (globalnych) zmiennych środowiskowych.
- Bieżący czas lub datę można pobrać za pomocą TIME$ i DATE$.
- Interpreter pozwala na samodzielną modyfikację kodu.
Graficzny interfejs użytkownika
W tym rozdziale opisano sposób korzystania z graficznego interfejsu użytkownika (GUI) wbudowanego w X11-Basic.
ALERT i FILESELECT
Dwa najczęściej używane interfejsy użytkownika to
graficzny wynik komunikatów potwierdzonych przez użytkownika,
selektor plików, w którym użytkownik może wybrać plik.
Oba są zaimplementowane jako w pełni funkcjonalne graficzne okno dialogowe.
Ponadto istnieją dodatkowe okna dialogowe do wyboru listy, proste pola wprowadzania tekstu, rozwijane menu i możliwość kompilowania dowolnych okien dialogowych z prostych obiektów. Można tworzyć dowolne dialogi za pomocą funkcji obiektu i zasobu.
Okno ALERT z wiadomością.
Rys. pokazuje typowe okno komunikatu. Polecenie generujące to:
ALERT 3,"This file is write protected.|You can only read or \ delete it.",1,"OK|DELETE|CANCEL",sel
Pola ALERT mogą być również używane do zarządzania prostymi formularzami wejściowymi.
Oto mały przykładowy program:
CLEARWi=1name$="TEST01"posx$="N54°50'32.3"posy$="E007°50'32.3"t$="Edit waypoint:||Name: "+CHR$(27)+name$+"|"t$=t$+"Breite: "+chr$(27)+posx$+"|"t$=t$+"Länge: "+chr$(27)+posy$+"|"t$=t$+"Höhe: "+chr$(27)+str$(alt,5,5)+"|"t$=t$+"Typ: "+chr$(27)+hex$(styp,4,4)+"|"ALERT 0,t$,1,"OK|UPDATE|LÖSCHEN|CANCEL",a,f$WHILE LEN(f$)WORT_SEP f$,CHR$(13),0,a$,f$PRINT "Feld";i;": ",a$INC iWENDQUIT
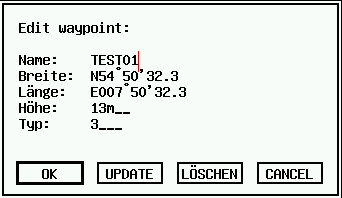
Pole ALERT z polami wprowadzania.
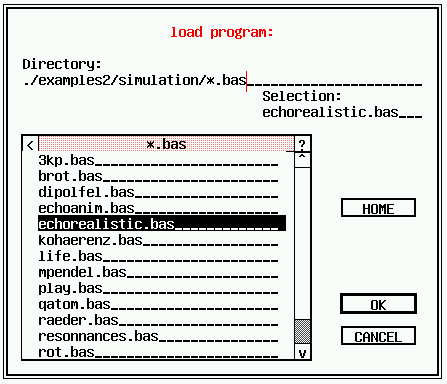
Okno wyboru pliku.
Rys. pokazuje pole wyboru pliku. Polecenie generujące to:
FILESELECT "load program:","./*.bas","in.bas",f$
Pełna ścieżka i nazwa pliku wybranego pliku jest zwracana w f$.
Menu rozwijane.
Zasoby X11 Basic składają się z drzew obiektów, łańcuchów i bitmap używanych przez program BASIC. Zawierają interfejs użytkownika i ułatwiają internacjonalizację umieszczając wszystkie ciągi wiadomości i podpisów w jednym osobnym pliku. Format danych zasobu X11 Basic jest kompatybilny wstecz z implementacją Atari-ST GEM.
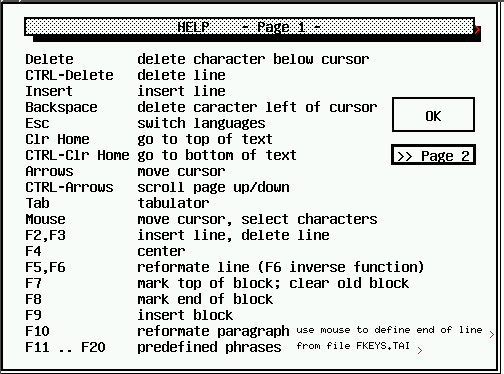
Bardziej złożone okno komunikatu.
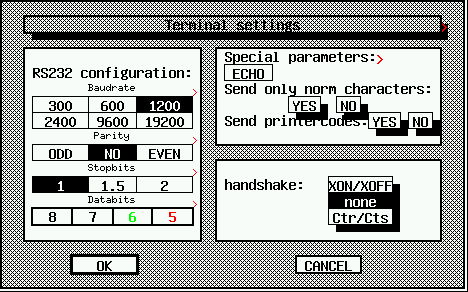
Bardziej złożone okno dialogowe wprowadzania danych.
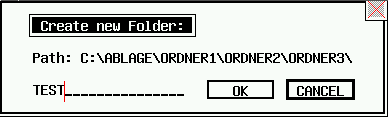
Bardziej złożony formularz wejściowy.
Ilustracje pokazują trzy przykłady bardziej złożonych okien dialogowych, które mogą być użyte w X11-Basic. Zasoby są zwykle tworzone przy użyciu zestawu do konstruowania zasobów (Resource Construction Set ) i przechowywane w pliku .RSC. Następnie jest ładowany przez RSRC_LOAD() w czasie inicjalizacji programu.
Zasoby można również osadzać jako struktury danych w kodzie źródłowym (narzędzia rsc2gui.bas i gui2bas.bas konwertują pliki .RSC do kodu źródłowego). Zasoby obejmują wskaźniki i współrzędne, które są dostosowane do bieżącego rozmiaru ekranu przed użyciem. RSRC_LOAD() robi to automatycznie, ale jeśli używasz osadzonego zasobu, musisz zająć się każdym obiektem w każdym drzewie obiektów, aby przekonwertować oryginalne współrzędne znaków na współrzędne ekranu. Dzięki temu zasoby utworzone na ekranach o różnych współczynnikach proporcji i czcionkach systemowych wyglądają tak samo. Po załadowaniu zasobu użyj rsrc_gaddr() aby uzyskać wskaźniki do poszczególnych drzew obiektów, którymi można następnie manipulować bezpośrednio lub za pomocą wbudowanych funkcji X11 Basic.
Obiekty graficznego interfejsu użytkownika
Obiektami mogą być pola, przyciski, tekst, obrazy i inne. Drzewo obiektów to tablica struktur OBJECT, które są ze sobą połączone, tworząc ustrukturyzowaną relację. Sam obiekt to obszar danych, który może być przechowywany w X11-Basic przez ciąg znaków.
Struktura OBJECT ma następujący format:
object$=MKI$(ob_next)+MKI$(ob_head)+MKI$(ob_tail)+
MKI$(ob_type)+MKI$(ob_flags)+MKI$(ob_state)+
MKL$(ob_spec)+MKI$(ob_x)+MKI$(ob_y)+MKI$(ob_width)+
MKI$(ob_height)
Drzewo obiektów to zbiór obiektów:
tree$ = object0$ + object1$ + ... + objectn$
Pierwszy obiekt w drzewie OBJECT nazywany jest obiektem ROOT (OBJECT 0). Współrzędne odnoszą się do lewego górnego rogu ekranu lub okna graficznego. Obiekt ROOT może mieć dowolną liczbę dzieci, a każde dziecko może mieć własne dzieci. W każdym razie, współrzędne obiektu są ob_x, ob_y, ob_width oraz ob_height, w odniesieniu do jego rodzica. Funkcja X11 Basic objc_offset() może być użyta do określenia dokładnych bezwzględnych współrzędnych ekranu obiektu podrzędnego. objc_find() służy do określenia obiektu, w którym leży określona współrzędna ekranu (np. wskaźnik myszy).
Pola ob_next, ob_head i ob_tail określają relacje między nadrzędnymi i podrzędnymi obiektami.
|
ob_next |
Indeks następnego (liczenie obiektów od pierwszego obiektu w drzewie obiektów) obiektu o tym samym rankingu (rodzeństwo) na tym samym poziomie w tablicy drzewa obiektów. Obiekt ROOT powinien ustawić tę wartość na -1. Ostatnie dziecko na danym poziomie drzewa obiektów powinno zawierać indeks rodzica. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ob_head |
Indeks pierwszego elementu potomnego bieżącego obiektu. Jeśli obiekt nie ma elementów podrzędnych, ta wartość powinna wynosić -1. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ob_tail |
Indeks ostatniego elementu podrzędnego: koniec listy obiektów podrzędnych obiektowi w tablicy drzewa obiektów. Jeśli obiekt nie zawiera elementów podrzędnych, wartość ta powinna wynosić -1. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ob_type |
Typ obiektu. Niski bajt pola ob_type określa typ obiektu w następujący sposób:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ob_flags |
Pole ob_flags struktury obiektu jest bit-maską różnych flag, które można zastosować do dowolnego obiektu. Możesz zastosować jedną lub więcej flag w tym samym czasie. Po prostu dodaj następujące wartości:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ob_state |
Pole ob_state określa stan wyświetlania obiektu w następujący sposób:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ob_spec |
Pole ob_spec zawiera różne dane w zależności od typu obiektu, jak pokazano w poniższej tabeli:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
objc_colorword |
Prawie wszystkie obiekty odnoszą się do typu WORD zawierającego zdefiniowany poniżej kolor obiektu.
objc_colorword = bbbbcccctpppcccc
Bity 15-12 kolor krawędzi Bity 11-8 kolor tekstu Bit 7 ma wartość 1, jeśli jest nieprzezroczysty lub 0, jeśli jest przezroczysty Bity 6- 4 wskaźnik wypełnienia wzoru Bity 3- 0 kolor wypełnienia
Dostępne kolory wypełnień, tekstu i obramowań są wymienione poniżej:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
TEDINFO |
Obiekty G_TEXT, G_BOXTEXT, G_FTEXT i G_FBOXTEXT wskazują na strukturę TEDINFO w swoim polu ob_spec. Struktura TEDINFO jest zdefiniowana następująco:
tedinfo$=MKL$(VARPTR(te_ptext$))+MKL$(VARPTR(te_ptmplt$))+ MKL$(VARPTR(te_pvalid$))+MKI$(te_font)+MKI$(te_fontid)+ MKI$(te_just)+MKI$(te_color)+MKI$(te_fontsize)+ MKI$(te_thickness)+MKI$(te_txtlen)+MKI$(te_tmplen)
Trzy wskaźniki wskazują na ciągi tekstowe wymagane przez obiekty G_FTEXT i G_FBOXTEXT. te_ptext wskazuje na faktyczny tekst do wyświetlenia i jest jedynym polem używanym przez wszystkie obiekty tekstowe. te_ptmpt wskazuje szablon tekstowy dla edytowalnych pól. Dla każdego znaku, który użytkownik może wprowadzić, ciąg tekstowy musi zawierać znak tyldy (ASCII 126). Inne znaki są wyświetlane, ale nie mogą zostać zmienione przez użytkownika. te_pvalid zawiera znaki sprawdzania poprawności dla każdego znaku, który może wprowadzić użytkownik. Poprawne znaki sprawdzania poprawności to:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
te_font |
może mieć następujące wartości:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
te_just |
określa wyrównanie tekstu w obiekcie i może mieć następujące wartości:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
te_thickness |
ustawia grubość krawędzi (wartości dodatnie i ujemne są dopuszczalne) obiektu G_BOXTEXT lub G_FBOXTEXT. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
te_txtlen i te_tmplen |
wskazuje długość tekstu początkowego i długość szablonu. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
BITBLK |
Obiekty G_IMAGE zawierają wskaźnik do struktury BITBLK w ich polu ob_spec. Struktura BITBLK jest zdefiniowana następująco:
bitblk$=MKL$(VARPTR(bi_pdata$))+MKI$(bi_wb)+MKI$(bi_hl)+ MKI$(bi_x)+MKI$(bi_y)+MKI$(bi_color)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
ICONBLK |
Pole ob_spec obiektu G_ICON wskazuje na strukturę ICONBLK, jak określono poniżej:
iconblk$=MKL$(VARPTR(ib_pmask$))+MKL$(VARPTR(ib_pdata$))+MKL$(VARPTR(ib_ptext$))+ MKI$(ib_char)+MKI$(ib_xchar)+MKI$(ib_ychar)+ MKI$(ib_xicon)+MKI$(ib_yicon)+MKI$(ib_wicon)+MKI$(ib_hicon)+ MKI$(ib_xtext)+MKI$(ib_ytext)+MKI$(ib_wtext)+MKI$(ib_htext)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
CICONBLK |
Obiekt G_CICON zawiera w polu ob_spec wskaźnik do struktury CICONBLK, jak określono poniżej:
ciconblk$=monoblk$+MKL$(VARPTR(mainlist$))
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
APPLBLK |
Obiekty G_PROGDEF pozwalają programistom definiować obiekty niestandardowe i płynnie je łączyć z drzewem obiektów. Pole ob_spec obiektów G_PROGDEF zawiera wskaźnik do struktury danych APPLBLK, jak określono poniżej:
applblk$=MKL$(SYM_ADR(#1,"function"))+MKL$(ap_parm)
Pierwszy to wskaźnik do niestandardowej procedury, która narysuje obiekt. Ta procedura musi być funkcją C, która musi być połączona z programem X11-Basic za pomocą polecenia LINK. Procedura przekazuje wskaźnik do struktury PARMBLK zawierającej informacje potrzebne do narysowania obiektu. ap_parm jest wartością zdefiniowaną przez użytkownika, która jest kopiowana do struktury PARMBLK w następujący sposób:
typedef struct parm_blk { OBJECT *tree; short pb_obj; short pb_prevstate; short pb_currstate; short pb_x; short pb_y; short pb_w; short pb_h; short pb_xc; short pb_yc; short pb_wc; short pb_hc; long pb_parm; } PARMBLK; |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
tree |
wskazuje drzewo OBJECT obiektu, który jest narysowany. Obiekt ma indeks pb_obj wewnątrz drzewa. Procedura przekazuje stare ob_state obiektu w pb_prevstate i nowe ob_state obiektu w pb_currstate. Jeśli pb_prevstate i pb_currstate są takie same, to obiekt powinien być narysowany w całości, w przeciwnym razie konieczne jest tylko tyle przerysowania, aby doprowadzić obiekt z pb_prevstate do nowego stanu pb_currstate. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
pb_x, pb_y, pb_w i pb_h |
określają współrzędne ekranu obiektu. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
pb_xc, pb_yc, pb_wc i pb_hc |
określają prostokąt obcinania. |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
pb_parm |
Zawiera kopię wartości ap_parm w strukturze APPLBLK.
Niestandardowa procedura powinna zwrócić wartość (typu short) zawierającą wszystkie pozostałe bity ob_state, które biblioteka GUI powinna następnie narysować na twoim niestandardowym obiekcie. |
Okna dialogowe to modalne formy wprowadzania danych przez użytkownika. Oznacza to, że nie ma już dalszej interakcji między użytkownikiem a aplikacją, dopóki wymagania okna dialogowego nie zostaną spełnione i okno dialogowe zostanie zamknięte. Normalne okno dialogowe składa się z drzewa obiektów z ramką (BOX) jako obiektu głównego i dowolnej liczby innych elementów sterujących akceptujących dane wprowadzone przez użytkownika. Zarówno komunikaty ALERT jak i wybór pliku (FILESELECT) są przykładami okien dialogowych.
Funkcja form_do() to najprostszy sposób użycia okna dialogowego, który przejmuje kontrolę nad myszą i klawiaturą oraz zarządza funkcją dialogu z użytkownikiem. Po prostu skonstruuj drzewo OBJECT z co najmniej jednym obiektem EXIT lub TOUCHEXIT, a następnie wywołaj form_do().
Wcześniej powinieneś wyświetlić okno dialogowe funkcją objc_draw(). Możesz również wyśrodkować okno dialogowe używając form_center() oraz za pomocą form_dial() zapisać tło i przywrócić je po zakończeniu okna dialogowego.
Cała interakcja z oknem dialogowym, polami wprowadzania, przyciskami opcji i wybieranymi obiektami jest obsługiwana niezależnie przez X11-Basic, dopóki użytkownik nie wybierze obiektu EXIT lub TOUCHEXIT.
Format pliku .gui jest w zasadzie reprezentacją ASCII plików zasobów ATARI ST (.rsc). Można je przekształcić w kod X11 Basic, który może następnie zawierać pola i formularze wiadomości. Konwerter gui2bas(1) właśnie to robi. Jest także przydatny konwerter plików zasobów ATARI ST do plików .gui - rsc2gui(1).
Plik .gui składa się z wierszy i bloków, należy określić obiekty i ich hierarchiczne zależności.
Ogólny format takiego obiektu to:
label: TYPE(zmienne) {
... blok ...
}
Etykieta jest opcjonalna i nadaje obiektowi nazwę. W zależności od typu obiektu, jedna lub więcej zmiennych jest określona w nawiasach jako lista rozdzielana przecinkami.
Każdy obiekt może uruchomić blok za pomocą { na końcu linii. W ramach tego bloku można zdefiniować jeden lub więcej obiektów, które są następnie uważane za pod-obiekty tego, kto otworzył blok. Blok zamyka się przez } w pojedynczej linii.
Przykład:
' Little selector box (c) Markus Hoffmann 07.2003
' convert this with gui2bas !
' as an example for the use of the gui system
' with X11-Basic
BOX(X=0,Y=0,W=74,H=14, FRAME=2, FRAMECOL=1, TEXTCOL=1, BGCOL=0, PATTERN=0, TEXTMODE=0, STATE=OUTLINED+) {
BOXTEXT(X=2,Y=1,W=70,H=1, TEXT="Select option ...", FONT=3, JUST=2, COLOR=4513, BORDER=253, STATE=SHADOWED+)
BOX(X=2,Y=3,W=60,H=10, FRAME=-1, FRAMECOL=1, TEXTCOL=1, BGCOL=0, PATTERN=0, TEXTMODE=0) {
FTEXT(X=1,Y=1,W=30,H=1,COLOR=4513,FONT=3,BORDER=1,TEXT="Line 1",
PTMP="_______________________________________",
PVALID="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", FLAGS=EDITABLE)
FTEXT(X=1,Y=2,W=30,H=1,COLOR=4513,FONT=3,BORDER=1,TEXT="",
PTMP="_______________________________________",
PVALID="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", FLAGS=EDITABLE)
FTEXT(X=1,Y=3,W=30,H=1,COLOR=4513,FONT=3,BORDER=1,TEXT="",
PTMP="_______________________________________",
PVALID="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", FLAGS=EDITABLE)
FTEXT(X=1,Y=4,W=30,H=1,COLOR=4513,FONT=3,BORDER=1,TEXT="",
PTMP="_______________________________________",
PVALID="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX", FLAGS=EDITABLE)
BOX(X=2,Y=6,W=50,H=3, FRAME=-1, FRAMECOL=1, TEXTCOL=1, BGCOL=1, PATTERN=5,
TEXTMODE=0) {
BUTTON(X=2,Y=1,W=4,H=1, TEXT="ON",STATE=SELECTED,
FLAGS=RADIOBUTTON+SELECTABLE,FRAME=2, FRAMECOL=1, TEXTCOL=1,
BGCOL=1, PATTERN=0, TEXTMODE=0)
BUTTON(X=8,Y=1,W=4,H=1, TEXT="OFF",FLAGS=RADIOBUTTON+SELECTABLE,FRAME=2,
FRAMECOL=1, TEXTCOL=1, BGCOL=1, PATTERN=0, TEXTMODE=0)
}
}
ok: BUTTON(X=65,Y=4,W=7,H=4, TEXT="OK", FLAGS=SELECTABLE+DEFAULT+EXIT)
cancel: BUTTON(X=65,Y=9,W=7,H=4, TEXT="CANCEL", FLAGS=SELECTABLE+EXIT+LASTOB+)
}
Większość aplikacji korzysta z paska menu, aby umożliwić użytkownikowi nawigację po opcjach programu.
Oto prosty przykładowy program demonstrujący sposób korzystania z rozwijanego menu:
' Test-program for Drop-Down-Menus'DIM field$(50)FOR i=0 TO 50READ field$(i)EXIT IF field$(i)="***"NEXT ioh=0field$(i)=""DATA "INFO"," Menutest"DATA "---------------"DATA "- Access.1","- Access.2","- Access.3","- Access.4","- Access.5"DATA "- Access.6",""DATA "FILE"," new"," open ..."," save"," save as ...","--------------"DATA " print","--------------"," Quit",""DATA "EDIT"," cut"," copy"," paste","----------"," help1"," helper"DATA " assist",""DATA "HELP"," online help","--------------"," edifac"," editor"," edilink"DATA " edouard",""DATA "***"grau=GET_COLOR(32000,32000,32000)COLOR grauPBOX 0,0,640,400MENUDEF field$(),menuactionDOPAUSE 0.05MENULOOPQUITPROCEDURE menuaction(k)LOCAL bIF (field$(k)=" Quit") OR (field$(k)=" exit")QUITELSE IF field$(k)=" online help"oh=not ohMENUSET k,4*abs(oh)ELSE IF field$(k)=" Menutest"~FORM_ALERT(1,"[0][- Menutest -||(c) Markus Hoffmann 2001|X11-Basic V.1.03][ OK ]")ELSEPRINT "MENU selected ";k;" contents: ";field$(k)b=FORM_ALERT(1,"[1][--- Menutest ---||You selected item (No. "+str$(k)+ \"),| for which was no|function defined !][ OK |disable]")IF b=2MENUSET k,8ENDIFENDIFRETURN
W tym rozdziale wyjaśniono, jak korzystać z programów X11 Basic dla interfejsów WEB. W szczególności poprzez użycie tak zwanych skryptów CGI.
Czym jest CGI
CGI oznacza Common Gateway Interface . W skrócie, CGI definiuje sposób, w jaki serwery sieciowe i przeglądarki internetowe przetwarzają informacje z formularzy HTML na stronach internetowych. Oznacza to, że zamiast wysyłania statycznych stron internetowych do klientów, serwer WWW może wywołać program, zazwyczaj nazywany skryptem CGI, generujący stronę w momencie otrzymania żądania. Te skrypty CGI podejmują pewne działania, a następnie zwracają stronę wynikową do przeglądarki internetowej użytkownika. Strona wynikowa może wyglądać inaczej przy każdym uruchomieniu programu.
A te skrypty mogą być programami X11 Basic.
1. Wszystkie skrypty X11 Basic muszą zaczynać się od następującej instrukcji w pierwszym wierszu:
#! / Usr / bin / XBasic
Ponieważ Unix nie ma specjalnych rozszerzeń plików dla programów, musisz poinformować system operacyjny (Unix), że ten plik jest programem X11 Basic i że powinien on być wykonywany przez interpreter xbasic. Działa to tak samo, jak w przypadku skryptów powłoki. Interpreter xbasic zwykle po instalacji znajduje się w katalogu /usr/bin. Ale w niektórych systemach może to być inny katalog. Jeśli nie masz pewności, gdzie znajduje się plik wykonywalny xbasic, wpisz which xbasic w wierszu poleceń, a otrzymasz w odpowiedzi ścieżkę.
2. Wszystkie skrypty muszą być oznaczone jako pliki wykonywalne.
Pliki wykonywalne to te, które zawierają instrukcje maszynowe lub kod dla interpretera xbasic. Aby oznaczyć plik jako wykonywalny musisz zmienić uprawnienia do pliku. Odbywa się to za pomocą następującego polecenia (z okna terminala):
chmod 755 filename.bas
Liczba 755 to maska dostępu do pliku. Pierwsza cyfra to twoje uprawnienie - 7 dla pełnego dostępu. Ustawienia dla innych to 5 do odczytu i wykonania (ale nie zmieniania).
3. Pierwsza instrukcja PRINT w skrypcie CGI X11 Basic, która zwraca HTML musi być następująca:
PRINT "Content-type: text/html"+CHR$(13) PRINT ""+CHR$(13) FLUSH
Jeśli twój skrypt X11 Basic zwraca dane HTML, musisz mieć to jako pierwszą instrukcję PRINT, aby powiedzieć serwerowi internetowemu, że jest to plik HTML. Aby to działało należy użyć dwóch znaków końca wiersza (CR + LF) (to wyjaśnia dodatkowe CHR$(13)). Instrukcja FLUSH zapewnia wysłanie tego oświadczenia na serwer WWW. Potem zwykle przychodzi
PRINT "<HTML><BODY>" .... i tak dalej ......
4. Koniec programu: QUIT.
W przeciwnym razie program CGI pozostaje w pamięci serwera jako zombie.
5. Zawsze używaj metody POST z formularzami HTML.
Istnieją dwa sposoby uzyskania informacji od klienta z powrotem na serwer WWW. Metoda GET pobiera wszystkie dane z formularzy i łączy je z końcem adresu URL. Ta informacja jest następnie przekazywana jako zmienna środowiskowa QUERY_STRING do programu CGI. Ponieważ metoda GET ma limit 1024 znaków, zalecamy użycie metody POST. Spowoduje to odebranie danych i wysłanie ich wraz z żądaniem do serwera WWW bez konieczności oglądania przez użytkownika brzydkich ciągów w adresie URL. Informacje te są przekazywane do programu CGI za pośrednictwem standardowego wejścia, które program CGI może z łatwością odczytać instrukcją LINEINPUT. Aby użyć metody POST, upewnij się, że masz tag formularza HTML postaci METHOD=POST (bez cudzysłowów).
6. Formularze HTML muszą odwoływać się do skryptu CGI, który ma zostać wykonany.
W tagu FORM znajduje się atrybut ACTION. Jest to podobne do atrybutu HREF dla łącza. Powinien to być adres URL programu CGI, do którego należy wysłać dane formularza. Zwykle wygląda to tak: ACTION="/cgi-bin/filename.bas".
7. Podstawowe pliki CGI X11 Basic muszą zwykle znajdować się w katalogu cgi-bin serwera WWW.
Każdy serwer sieciowy ma katalog główny. Jest to najwyższy katalog, do którego mogą uzyskać dostęp pliki HTML. (Nie chcesz, aby klienci mogli przeszukiwać cały system.). W tym katalogu jest zwykle katalog cgi-bin, w którym przechowywane są wszystkie programy CGI. Tylko tam można je uruchomić. Niektórzy dostawcy usług internetowych udostępniają każdemu użytkownikowi swój lokalny katalog cgi w swoim katalogu domowym, w którym mogą umieszczać swoje skrypty CGI. Jeśli tak jest, użyj tego katalogu.
Gdy użytkownik aktywuje łącze do skryptu bramy, dane są wysyłane na serwer. Serwer formatuje te dane do zmiennych środowiskowych i sprawdza, czy dodatkowe dane zostały przesłane przez standardowy strumień wejściowy. Zmienne środowiskowe można następnie wykorzystać w skrypcie CGI.
Zmienne środowiskowe
Dane wejściowe dla skryptów CGI są zwykle przekazywane w zmiennych środowiskowych. Dane są przekazywane przez przeglądarkę, która wyświetla stronę.
W zmiennych środowiskowych rozróżniana jest wielkość liter i są one zazwyczaj używane w sposób opisany w tej sekcji. Niektóre standardowe (i niezależne od platformy) zmienne środowiskowe są wymienione w poniższej tabeli:
|
zmienna |
znaczenie |
|
AUTH_TYPE |
Określa metodę uwierzytelniania i służy do weryfikacji dostępu użytkownika. |
|
CONTENT_LENGTH |
Długość ciągu danych jako wartość liczbowa. |
|
CONTENT_TYPE |
Typ MIME danych. |
|
GATEWAY_INTERFACE |
Wskazuje, której wersji standardu CGI używa serwer. |
|
HTTP_ACCEPT |
Określa typy MIME, które przeglądarka akceptuje, gdy są przekazywane przez serwer do skryptu bramy. |
|
HTTP_USER_AGENT |
Określa typ przeglądarki używanej do wysyłania żądania. |
|
PATH_INFO |
Identyfikuje dodatkowe informacje w adresie URL po zidentyfikowaniu skryptu CGI. |
|
PATH_TRANSLATED |
Ustawione przez serwer na podstawie zmiennej PATH_INFO. Serwer tłumaczy zmienną PATH_INFO na tę zmienną. |
|
QUERY_STRING |
Ciąg zapytania (jeśli URL zawiera ciąg zapytania). |
|
REMOTE_ADDR |
Identyfikuje adres IP komputera zdalnego, który wysyła żądanie. |
|
REMOTE_HOST |
Nazwa komputera wysyłającego żądanie. |
|
REMOTE_IDENT |
Identyfikator komputera komputera wysyłającego żądanie. |
|
REMOTE_USER |
Nazwa użytkownika do uwierzytelnienia użytkownika |
|
REQUEST_METHOD |
Określa metodę, poprzez którą zostało wysłane żądanie. |
|
SCRIPT_NAME |
Identyfikuje wirtualną ścieżkę do wykonywanego skryptu. |
|
SERVER_NAME |
Identyfikuje serwer za pomocą jego nazwy hosta, aliasu lub adresu IP. |
|
SERVER_PORT |
Określa numer portu, przez który serwer otrzymał żądanie. |
|
SERVER_PROTOCOL |
Określa protokół żądania wysłanego na serwer. |
|
AUTH_TYPE |
Zmienna "AUTH_TYPE" zapewnia kontrolę dostępu do chronionych obszarów serwera WWW i może być używana tylko na serwerach obsługujących uwierzytelnianie użytkowników. Jeśli obszar witryny ma kontrolę dostępu, zmienna "AUTH_TYPE" jest ustawiona na wartość wskazującą zastosowany schemat uwierzytelniania. Np. "Basic". Za pomocą tego mechanizmu serwer może wysyłać zapytania i weryfikować nazwę użytkownika i hasło. Aby to zrobić, serwer ustawia wartość dla zmiennej AUTH_TYPE, a klient zwraca odpowiednią wartość. Następnym krokiem jest uwierzytelnienie użytkownika. Korzystając z podstawowego schematu uwierzytelniania, przeglądarka użytkownika musi podać informacje uwierzytelniające, które jednoznacznie identyfikują użytkownika. Ta informacja zawiera identyfikator użytkownika i hasło. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
CONTENT_LENGTH |
Zmienna CONTENT_LENGTH zapewnia sposób określenia długości sekwencji danych, które klient chce wysłać do serwera za pośrednictwem standardowego strumienia wejściowego. Wartość zmiennej odpowiada liczbie znaków w danych przekazanych wraz z żądaniem. Jeśli nie przekazano żadnych danych, zmienna nie ma wartości. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
CONTENT_TYPE |
Zmienna CONTENT_TYPE określa typ MIME danych. Ta zmienna jest ustawiana tylko podczas dołączania danych do standardowego strumienia wejściowego lub wyjściowego. Wartość przypisana do zmiennej identyfikuje podstawowy typ i podtyp MIME w następujący sposób:
Podtypy MIME są podzielone na trzy kategorie: podstawową, dodatkowo zdefiniowaną i rozwiniętą. Podstawowym podtypem jest podstawowy typ danych używany do użycia jako typ zawartości MIME. Dodatkowo zdefiniowane typy danych są zawsze podtypami, które zostały oficjalnie przyjęte jako typy zawartości MIME. Rozszerzone typy danych to eksperymentalne podtypy, które nie zostały oficjalnie przyjęte jako typy zawartości MIME. Możesz łatwo zidentyfikować rozszerzone podtypy, ponieważ zaczynają się od litery x, po której następuje myślnik. Poniższa tabela zawiera listę typowych typów MIME i ich opisy:
Zauważ, że istnieje nawet więcej typów niż wymienione powyżej. Niektóre typy zawartości MIME mogą być używane z dodatkowymi parametrami. Należą do nich typy treści text/plain, text/html i wszystkie wieloczęściowe dane komunikatu. Opcjonalny parametr charset jest używany z typem text/plain w celu określenia zestawu znaków używanych w danych. Jeśli nie zostanie podany żaden zestaw znaków, przyjmowana jest wartość domyślna charset=us-ascii. Inne wartości zestawu znaków obejmują wszystkie zestawy znaków, które zostały zatwierdzone przez Międzynarodową Organizację Norm. Czcionki te są zdefiniowane przez ISO-8859-1 do ISO-8859-9 i można je określić w następujący sposób:
CONTENT_TYPE = text/plain; charset=iso-8859-1
W przypadku danych wieloczęściowych wymagany jest parametr boundary do określenia ciągu granicznego oddzielającego części wiadomości. Łańcuch może mieć od 1 do 70 znaków i może zawierać dowolne litery, cyfry, spacje i ograniczoną liczbę znaków specjalnych, ale nie może kończyć się spacją. Musi być unikalny i nie może występować w częściach wiadomości. Oto, jak to wygląda:
CONTENT_TYPE = multipart/mixed; boundary=boundary_string
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
GATEWAY_INTERFACE |
Zmienna GATEWAY_INTERFACE wskazuje, której wersji specyfikacji CGI używa serwer. Wartość przypisana do zmiennej identyfikuje nazwę i wersję specyfikacji używanej w następujący sposób:
GATEWAY_INTERFACE = name/version
Wersja specyfikacji CGI to 1.1. Serwer zgodny z tą wersją ustawi GATEWAY_INTERFACE w następujący sposób:
GATEWAY_INTERFACE = CGI/1.1
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
HTTP_ACCEPT |
Zmienna HTTP_ACCEPT określa typy danych akceptowane przez klienta. Dopuszczalne wartości są wyrażone odpowiednio jako pary "typ / podtyp". Każda para typu / podtypu jest oddzielona przecinkami. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
HTTP_USER_AGENT |
Zmienna HTTP_USER_AGENT określa typ przeglądarki używanej do wysyłania żądania. Dopuszczalne wartości są wyrażone jako "typ oprogramowania / wersja" lub biblioteka / wersja. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
PATH_INFO |
Zmienna PATH_INFO określa dodatkowe informacje o ścieżce i może być używana do wysyłania dodatkowych informacji do skryptu bramy. Dodatkowe informacje o ścieżce są zgodne z adresem URL skryptu bramy, do której istnieje odwołanie. Ogólnie rzecz biorąc, ta informacja jest wirtualną lub względną ścieżką do zasobu, który serwer musi zinterpretować. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
PATH_TRANSLATED |
Serwery tłumaczą zmienną PATH_INFO na zmienną PATH_TRANSLATED wstawiając ścieżkę do katalogu domyślnego dokumentu internetowego przed dodatkowymi informacjami o ścieżce. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
QUERY_STRING |
Zmienna QUERY_STRING określa zakodowany ciąg znaków wyszukiwania. Ustawiasz tę zmienną, gdy używasz metody GET do przesłania formularza. Ciąg zapytania jest oddzielony od adresu URL znakiem zapytania. Użytkownik wysyła dowolne informacje po znaku zapytania oddzielającym adres URL od ciągu zapytania. Oto przykład:
URL: /cgi-bin/doit.cgi?word1+word2+word3
Znak plus jest substytutem spacji. Znaki równości oddzielają słowa kluczowe określone przez stronę od wartości wprowadzonych przez użytkownika. W poniższym przykładzie słowo kluczowe to "response", a wartość wprowadzona przez użytkownika to "never":
URL: /cgi-bin/doit.cgi?response=never
Symbols ampersand (&) oddziela pary klucz / wartość. W poniższym przykładzie pierwszy klucz "response" otrzymuje wartość "sometimes", a drugi klucz "reason" otrzymuje wartość "I+am+not+really+sure":
URL: /cgi-bin/doit.cgi?response=sometimes&reason=I+am+not+really+sure
Znak procentu służy do identyfikacji znaków specjalnych. Po znaku procentu następuje kod wyjścia dla specjalnego znaku wyrażonego jako wartość szesnastkowa. Na przykład poprzedni ciąg zapytania mógł zostać zapisany przy użyciu kodu wyjściowego dla apostrofu:
URL: /cgi-bin/doit.cgi?response=sometimes&reason=I%27m+not+really+sure
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
REMOTE_ADDR |
Zmienna REMOTE_ADDR jest ustawiona na adres IP (Internet Protocol) zdalnego komputera, który wysyła żądanie. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
REMOTE_HOST |
Zmienna REMOTE_HOST określa nazwę komputera hosta, który wysyła żądanie. Ta zmienna jest ustawiona tylko wtedy, gdy serwer może określić tę informację, żądając nazwy serwera. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
REMOTE_IDENT |
Zmienna REMOTE_IDENT identyfikuje użytkownika, który zgłasza żądanie. Zmienna jest ustawiana tylko wtedy, gdy serwer i komputer, który wysyła żądanie, obsługują protokół identyfikacji. Ponadto informacje o użytkowniku nie zawsze są dostępne, więc nie należy na nich polegać. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
REMOTE_USER |
Zmienna REMOTE_USER jest nazwą użytkownika, który został uwierzytelniony, i jest jedyną taka zmienną, na której możesz polegać w celu jego identyfikacji. Podobnie jak inne rodzaje uwierzytelniania użytkownika, ta zmienna jest ustawiona tylko wtedy, gdy serwer obsługuje uwierzytelnianie użytkownika. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
REQUEST_METHOD |
Zmienna REQUEST_METHOD określa metodę, którą zostało wysłane żądanie. Metody to: GET, HEAD, POST, PUT, DELETE, LINK i UNLINK. Metody GET, HEAD i POST są najczęściej używanymi. Zarówno GET, jak i POST są używane do przesyłania formularzy. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
SCRIPT_NAME |
określa wirtualną ścieżkę do uruchomionego skryptu. Ta informacja jest przydatna, jeśli skrypt generuje dokument HTML, który odwołuje się do skryptu. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
SERVER_NAME |
identyfikuje serwer za pomocą jego nazwy hosta, aliasu lub adresu IP. Ta zmienna jest zawsze ustawiona. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
SERVER_PORT |
określa numer portu, na którym serwer otrzymał żądanie. Informacje te można uzyskać w razie potrzeby z adresu URL do skryptu. Jednak większość serwerów używa domyślnego portu 80 dla żądań HTTP. |
||||||||||||||||||||||||||||||||||||||||||||||||
|
SERVER__PROTOCOL |
identyfikuje protokół używany do wysyłania żądania. Wartość przypisana do zmiennej identyfikuje nazwę i wersję używanego protokołu. Format to "nazwa / wersja", np. HTTP / 1.0. |
Większość danych wysyłanych na serwer sieciowy jest przechowywana w zmiennych środowiskowych, ale nie wszystkie dane wejściowe pasują do zmiennej środowiskowej. Kiedy użytkownik przesyła dane do przetworzenia przez skrypt bramy, dane te są odbierane jako łańcuch wyszukiwania zakodowany za pomocą adresu URL lub przez standardowy strumień wejściowy. Serwer wie, jak przetwarzać te dane, ponieważ do przesłania danych używana jest metoda (POST lub GET w HTTP 1.0).
Przesyłanie danych przez standardowe wejście jest najbardziej bezpośrednią metodą wysyłania danych. Serwer informuje skrypt bramy, ile bajtów należy odczytać ze standardowego wejścia. Następnie skrypt otwiera standardowy strumień wejściowy i odczytuje określoną ilość danych. Długie ciągi wyszukiwania zakodowane w URL mogą być obcięte. Dane wysyłane za pośrednictwem standardowego strumienia wejściowego będą zawsze całkowicie zachowane bez względu na długość. W związku z tym standardowy strumień wejściowy jest lepszym sposobem przekazywania danych.
Z jakiej metody danych wejściowych CGI należy korzystać
Możesz określić metodę dostarczania danych podczas tworzenia
formularzy internetowych. Istnieją dwie metody wprowadzania
formularzy. Metoda HTTP GET używa ciągów wyszukiwania zakodowanych w
adresie URL. Gdy serwer odbiera ciąg znaków zakodowany za pomocą
adresu URL, przypisuje wartość szukanego ciągu do zmiennej
QUERY_STRING.
Metoda HTTP POST wykorzystuje domyślne strumienie wejściowe. Kiedy
serwer otrzymuje dane za pośrednictwem standardowego strumienia
wejściowego, serwer przypisuje zmiennej CONTENT_LENGTH
ich długości w bajtach. Ze skryptu CGI można odczytać dane na
przykład za pomocą INPUT$().
Możesz zapoznać się z niektórymi przykładowymi programami X11 Basic, aby znaleźć metodę, która będzie odpowiadać twojemu celowi.
Po tym, jak skrypt odczyta i przetworzy dane wejściowe, powinien zwrócić jakieś dane wyjściowe do serwera. Serwer następnie wyśle dane wyjściowe z powrotem do klienta. Ogólnie rzecz biorąc, dane wyjściowe mają postać odpowiedzi HTTP, czyli nagłówek z pustą linią, a następnie tekst rzeczywisty, który może następnie zawierać kod HTML. Na przykład treść może zawierać dokument HTML, który powinien wyświetlić klient.
Nagłówki CGI zawierają instrukcje dla serwera. Obecnie te trzy dyrektywy serwera są prawidłowe:
Content-Type
Location
Status
Pojedynczy nagłówek może zawierać jedną lub wszystkie dyrektywy serwera. Twój skrypt CGI przekazuje te instrukcje na serwer. Chociaż po nagłówku występuje pusta linia oddzielająca nagłówek od treści, dane wyjściowe nie muszą zawierać treści.
Pole Content-Type w nagłówku CGI identyfikuje typ danych MIME wysyłanych do klienta. Zazwyczaj wynikiem działania skryptu jest w pełni sformatowany dokument, taki jak dokument HTML. Możesz określić to wyjście w nagłówku w następujący sposób:
Content-Type: text/html
Ale jeśli twój program wyprowadza inne dane, takie jak obrazy itp., powinieneś oczywiście określić odpowiedni typ zawartości.
LOKALIZACJE
Wynik twojego skryptu nie musi być dokumentem utworzonym w skrypcie. Możesz odwoływać się do dowolnego dokumentu w Internecie przy użyciu pola Location. Pole Location może wskazywać na plik określony przez jego adres URL. Serwery przetwarzają te odniesienia bezpośrednio lub pośrednio w zależności od lokalizacji pliku. Jeśli serwer może znaleźć plik lokalnie, przekazuje plik do klienta. W przeciwnym razie serwer przekierowuje adres URL do klienta, a klient musi pobrać sam plik. Możesz określić lokalizację w skrypcie w następujący sposób:
Location: http://www.new-jokes.com/
STATUS
Pole Status przekazuje wiersz statusu do serwera w celu przekazania do klienta. Kody statusowe są wyrażane w postaci trzycyfrowego kodu, po którym następuje ciąg znaków, który ogólnie wyjaśnia, co się stało. Pierwsza cyfra kodu statusu wskazuje ogólny stan w następujący sposób:
1XX Not yet allocated 2XX Success 3XX Redirection 4XX Client error 5XX Server error
Mimo że używanych jest wiele kodów stanu serwera, kody stanu przesyłane do klienta za pośrednictwem skryptu CGI są zwykle kodami błędów klienta. Załóżmy na przykład, że skrypt nie może znaleźć pliku, a Ty wskazałeś, że w takich przypadkach skrypt powinien zwrócić kod błędu zamiast zwracać nic. Oto lista kodów błędów klienta, których możesz użyć:
401 Unauthorized Authentication has failed.
Użytkownik nie ma praw dostępu do tego pliku. Musi się uwierzytelnić.
403 Forbidden. The request is not acceptable.
Użytkownik nie ma dostępu do pliku.
404 Not found.
Nie można znaleźć określonego pliku lub danych.
405 Method not allowed.
Metoda transmisji nie jest tutaj dozwolona.
Oto prosty przykład skryptu CGI, który po prostu zwraca wszelkie informacje, które otrzymuje z serwera WWW, jako stronę HTML.
#!/usr/bin/xbasic PRINT "Content-type: text/html"+CHR$(13) PRINT ""+CHR$(13) FLUSH PRINT "<html><head><TITLE>Test CGI</TITLE><head><body>" PRINT "<h1>Commandline:</h1>" i=0 WHILE LEN(PARAM$(i)) PRINT STR$(i)+": "+PARAM$(i)+"<br>" INC i WEND PRINT "<h1>Environment:</h1><pre>" FLUSH ! flush the output before another program is executed ! SYSTEM "env" PRINT "</pre><h1>Stdin:</h1><pre>" length=VAL(ENV$("CONTENT_LENGTH")) IF length FOR i=0 TO length-1 t$=t$+CHR$(inp(-2)) NEXT i PRINT t$ ENDIF PRINT "</pre>" PRINT "<FORM METHOD=POST ACTION=/cgi-bin/envtest.cgi>" PRINT "Name: <INPUT NAME=name><BR>" PRINT "Email: <INPUT NAME=email><BR>" PRINT "<INPUT TYPE=submit VALUE="+CHR$(34)+"Test POST Method"+CHR$(34)+">" PRINT "</FORM>" PRINT "<hr><h6>(c) Markus Hoffmann cgi with X11-basic</h6></body></html>" FLUSH QUIT
Istnieje kilka zarezerwowanych zmiennych lub nazw zmiennych.
Ponadto niektóre słowa kluczowe mogą nie działać jako nazwy
zmiennych. Chociaż interpreter nie sprawdza bezpośrednio nazw
zmiennych, mogą wystąpić błędy składni podczas przypisań. Spróbuj
polecenia LET w takich przypadkach.
Dopóki rozszerzenie nazwy zmiennej różni się od polecenia lub słowa
kluczowego, można go używać jako nazwy.
Zarezerwowane i zmienne systemowe to:
|
typ |
nazwa |
opis |
|
int |
|
daje -1 na systemach Android, w przeciwnym razie 0 |
|
int |
|
Liczba znaków w wierszu w terminalu tekstowym |
|
int |
|
Położenie kursora tekstu: bieżąca kolumna w terminalu tekstowym |
|
int |
|
Położenie kursora tekstu: bieżąca linia w terminalu tekstowym |
|
flt |
|
CPU System Timer (w sekundach) |
|
int |
|
Numer ostatniego błędu, który wystąpił |
|
int |
|
Stała: 0 |
|
int |
|
-1, jeśli GPS jest dostępny, w przeciwnym razie 0 |
|
flt |
|
Wysokość nad poziomem morza w metrach z GPS |
|
flt |
|
Szerokość geograficzna w stopniach z GPS |
|
flt |
|
Długość geograficzna w stopniach z GPS |
|
int |
|
Status przycisków myszy (reprezentacja bitów) |
|
int |
|
Stan klawiszy Shift, Alt, Ctrl, Caps |
|
int |
|
Współrzędna x pozycji myszy względem początku okna |
|
int |
|
Współrzędna y pozycji myszy względem początku okna |
|
int |
|
licznik programu: numer linii następnego wiersza do wykonania |
|
flt |
|
Stała: 3,14159265359 ... |
|
int |
|
Liczba linii w terminalu tekstowym |
|
int |
|
-1, jeżeli czujniki są dostępne, w przeciwnym razie 0 |
|
int |
|
Wewnętrzny wskaźnik stosu (głębokość zagnieżdżania) |
|
int |
|
Całkowity czas systemowy w sekundach |
|
flt |
|
Zegar systemowy Unix w sekundach |
|
int |
|
Stała: -1 |
|
int |
|
-1, jeśli system operacyjny jest podobny do systemu UNIX (Linux, BSD) |
|
int |
|
-1, jeśli system operacyjny to MS WINDOWS 32-bitowy |
|
|
Aktualna data |
|
|
|
Zapytanie o zdarzenie systemowe |
|
|
|
Zawartość bufora klawiatury |
|
|
|
Nazwa standardowego terminala |
|
|
|
Aktualny czas |
|
|
|
Bieżąca linia kodu programu |
Zauważ, że nie możesz przypisać niczego do tych zmiennych. Zawsze mają swoją wartość w zależności od funkcji.
Warunki i wyrażenia są takie same, FALSE są
zdefiniowane jako 0 i TRUE -1.
operatory logiczne, takie jak AND, OR,
XOR itd. są stosowane jako operacji
bitowej. W ten sposób można ich używać zarówno w wyrażeniach, jak i w
warunkach.
Stałe liczbowe można również reprezentować przedrostkiem 0x
dla wartości szesnastkowych. Stałe ciągów są oznaczone parami "".
Stałe tablicowe mają następujący format: [ , , ; , ; , , ].
Priorytet jest zdefiniowany następująco (najwyższy pierwszy):
() (Nawiasy)
^ (Potęga)
* / (Mnożenie, dzielenie)
\ (Reszta)
- + (Odejmowanie dodawanie)
MOD DIV (Moduł, dzielenie
całkowite)
< > = <> ⇐ >=
(Operatory porównania)
AND OR XOR NOT EQV IMP (Operatory
logiczne)
Operatory macierzowe -
Operatory macierzy na polach. W zależności od typu pola i wymiaru mogą mieć różne znaczenia.
Ponadto istnieją operatory / funkcje, które działają między różnymi klasami zmiennych, np.:
a%=INT(b), c=DET(d()), s=SMUL(a(),b()), a=NULL(2,4,5), ...
W szczególności odnosi się do operatora redukcji: a(:,3)
jest jednowymiarowym wektorem, a mianowicie kolumną nr 3
macierzy a.
W interpreterze każde polecenie może być skrócone, o ile parser
poleceń może jednoznacznie zidentyfikować polecenie. Więc możesz użyć
q zamiast QUIT.
Ponadto istnieją skróty, które są w rzeczywistości alternatywnymi poleceniami, takimi jak:
" - Skrót dla REM ? - Skrót od PRINT @ - Skrót od GOSUB lub wywołanie funkcji ~ - Skrót od VOID ! - Komentarz za linią & - Polecenie pośrednie
CLEAR czyści i usuwa wszystkie zmienne z pamięci CONT Kontynuacja programu (po STOP) DUMP Wyświetla wszystkie używane nazwy zmiennych DUMP "@" Wyświetla wszystkie funkcje i procedury DUMP ":" Wyświetla wszystkie etykiety DUMP "#" Wyświetla wszystkie otwarte pliki DUMP "K" Wyświetla listę wszystkich zaimplementowanych poleceń DUMP "F" Wyświetla wszystkie wewnętrzne funkcje ECHO ON/OFF tak samo jak TRON * TROFF EDIT Wywołuje edytor aby edytować program. HELP <expr> Wydrukuj krótki przewodnik dla słowa kluczowego. LIST [s, e] Wyświetla listę linii programu (od linii s do e) LOAD plik$ Ładuje program NEW Usuwa program i wszystkie zmienne z pamięci. PLIST Zwraca sformatowaną listę programu PROGRAM opcje Ustawia tytuł programu i opcje kompilatora QUIT opuszcza interpreter X11 BASIC (i kończy program) REM komentarz Komentarz do programu RUN Uruchamia program STOP Zatrzymuje program SAVE [plik$] Zapisuje program w pliku TROFF Wyłącza tryb śledzenia TRON Włącza tryb śledzenia (do rozwiązywania problemów) VERSION Pokazuje numer i datę wersji X11-Basic XLOAD Wybór pliku programu do załadowania XRUN Wybór pliku programu do uruchomienia
AFTER n, procedura Wywołuje procedurę po n sekundach BREAK To samo, co EXIT IF TRUE CASE const SELECT * CASE * DEFAULT * ENDSELECT CHAIN bas$ Wywołuje inny program X11-Basic CONTINUE SELECT * CASE * CONTINUE * ENDSELECT DEFAULT SELECT * CASE * DEFAULT * ENDSELECT DEFFN Definiuje makro-funkcję DO * LOOP Pętla(nieskończona) DOWNTO FOR ... DOWNTO ELSE patrz IF * ELSE * ENDIF ELSE IF patrz IF * ELSE * ENDIF END Koniec programu, powrót do trybu bezpośredniego ENDFUNKCTION FUNCTION * ENDFUNCTION ENDIF IF * ELSE * ENDIF ENDSELECT SELECT * CASE * DEFAULT * ENDSELECT EVERY n, procedura Wywołuje procedurę co n sekund EXIT IF a Opuść pętlę, jeśli warunek jest spełniony FOR * NEXT Pętla FUNCTION * ENDFUNC Definiowanie funkcji GOSUB proc (...) Wywołaj podprogram GOTO etykieta Idź do etykiety IF * ELSE * ENDIF Bloki warunkowe LOOP DO * LOOP NEXT FOR * NEXT ON BREAK GOSUB proc Definiuje procedurę przerwania programu ON ERROR GOSUB proc Definiuje procedurę obsługi błędów ON * GOSUB proc1, ... Wywołuje procedurę z listy procedur, w zależności od wartości ON * GOTO etykieta1,... Rozgałęzienie do różnych etykiet w zależności od wartości PAUSE sek Zatrzymuje wykonywanie programu na sek sekund REPEAT REPEAT * UNTIL RESUME Kontynuuj program po błędzie RETURN Definiuje koniec procedury lub zwraca wartość SELECT expr SELECT * CASE * DEFAULT * ENDSELECT UNTIL exp REPEAT * UNTIL SPAWN procedura Tworzy nowy wątek
Polecenia wejścia / wyjścia konsoli tekstowej
BEEP Dźwięk dzwonka (na TTY / konsoli) BELL Jak BEEP CLS Czyść ekran (tekstowy) FLUSH Wyjście flush HOME Kursor tekstowy w lewym górnym rogu INPUT "text"; lista Przypisz dane wejściowe użytkownika do listy zmiennych LINEINPUT t$ Czytaj całą linię z kanału / pliku / konsoli LOCATE wiersz, kol Umieść kursor tekstowy w kolumnie / wierszu PRINT a; b$ Wypisz tekst lub dane na wyjściu konsoli. PRINT AT(x, y); Umieść kursor tekstowy w kolumnie x / linii y PRINT COLOR (x, y); Ustaw kolor tekstu PRINT TAB(x); Umieść kursor tekstowy w kolumnie x PRINT SPC(x); Przesuń kursor tekstu o x kolumn w prawo PRINT a USING f$ Wypisz sformatowaną liczbę na konsoli PUTBACK a Zwróć znak do konsoli
Polecenia wejścia / wyjścia dla plików
BGET #f, a, n Wczytaj n bajtów z pliku #f pod adres a BLOAD f$, a[, l] Wczytaj cały plik o nazwie f$ pod adres a BPUT #f, a, n Zapisuje n bajtów adresu a do pliku / kanału f BSAVE f$, a, l Zapisuje l bajtów z adresu a w pamięci do pliku f$ CHDIR sciezka$ Zmień bieżący katalog roboczy CHMOD plik$, m Ustaw uprawnienia pliku CLOSE [[#]n] Zamknij otwarty plik, kanał I / O lub łącze FLUSH [#n] Wyjście flush KILL plik$ Usuń plik MAP mapuje plik do pamięci UNMAP "Odmapowuje" pamięć MKDIR ścieżka$ Utwórz folder plików OPEN m$, #n, plik$ Otwórz plik lub gniazdo do odczytu i / lub zapisu OUT #n, a Wysłanie bajtu a do kanału n PRINT #n; Napisz w pliku lub kanale PUTBACK [#n,]a Zwraca znak a do pliku, kanału lub konsoli RELSEEK #n, d Umieść wskaźnik pliku w nowej względnej pozycji RENAME plik$, dst$ Zmień nazwę lub przenieś plik RMDIR ścieżka$ Usuń pusty folder plików SEEK #n, d Umieść wskaźnik pliku w nowej pozycji bezwzględnej TOUCH #n Aktualizuj znacznik czasu otwartego pliku WATCH plik$ Śledzenie zmian pliku
ABSOLUTE x, adr% Przypisuje adres adr% pamięci do zmiennej x. ARRAYCOPY dst(), src() Kopiuje tablicę (łącznie z wymiarowaniem) ARRAYFILL a(), b Wypełnia tablicę wartością CLR a, b, c(), f$ Usuwa zawartość zmiennej: a=0; b=0; c()=[]; f$="" DEC zmienna Zmniejsza zmienną o 1 DIM Deklaruje tablicę ERASE a()[, ...] Usuwa tablicę (włączając wymiarowanie) INC a Zwiększenie zmiennej a o 1 (a=a+1) LET a = b Przepisane zmiennej b do a LOCAL zmienna [, ...] Deklaracja zmiennych lokalnych w proc. lub funkcji SORT a(), n[,b()] Sortuj tablicę SWAP a, b Wymień zawartość zmiennych VAR zmienne Deklaruje argumenty referencyjne funkcji
Polecenia dotyczące manipulacji pamięcią
ABSOLUTE x, adr% Przypisuje adres adr% pamięci do zmiennej x. BMOVE q, z, n Kopiuje blok n bajtów z adresu q do z DPOKE adres, słowo Zapisz słowo 'short int' do adresu pamięci FREE adr% Zwolnij poprzednio zarezerwowany blok pamięci LPOKE adr, long Napisz wartość 'long int' do adresu pamięci MFREE adr% Zwolnij poprzednio zarezerwowany blok pamięci. MSYNC adr%, l Zrzuca zmiany mapy pamięci z powrotem na dysk POKE adr, bajt Zapisz bajt do adresu adr SHM_DETACH adr% Odłącz segment pamięci wspólnej SHM_FREE adr% Zwolnij segment pamięci wspólnej
ADD a, b Jak a = a + b, ale szybciej
DEC var var = var-1, ale szybciej
DIV a, b a = a / b, ale szybciej
FFT a(), i Szybka transformata Fouriera na macierzy 1D
FIT x(), y()[,yerr()], n, func(x, a, b, c, ...)
Dopasuj funkcję do danych
FIT_LINEAR x(), y()[,[xerr(),]yerr()], n, a, b[, siga, sigb, chi2, q]
Regresja liniowa z błędami
FIT_POLY x(), y(), dy(), n%, a(), m%
Dopasuj wielomian do punktów danych
INC var var = var + 1, ale szybciej
MUL a, b a = a * b, ale szybciej
SORT a(), n[,b()] Sortuj wartości a() w porządku rosnącym
SUB a, b a = a - b, ale szybciej
CALL adr[, par, ...] Zobacz EXEC CONNECT #n, t$[, i%] Połącz z kanałem DATA 1, "Hello", ... Zapis danych w kodzie programu DELAY sec Zobacz PAUSE ERROR n Wywołuje błąd o numerze n EVAL t$ Wykonuje polecenie X11-Basic zawarte w t$ EXEC adr[, var, ...] Wywołuje podprogram C pod adresem adr. GET_LOCATION ,,,,,,, Zwraca położenie geograficzne urządzenia GPS ON / OFF Włącza lub wyłącza odbiornik GPS LINK #n, t$ Ładuje plik obiektu współdzielonego t$ UNLINK #n Usuwa obiekt współdzielony z pamięci MERGE f$ Dodaj plik .bas do bieżącego programu NOP Nie rób nic NOOP Nie rób nic PAUSE sek Zatrzymuje wykonywanie programu na sek sekund PIPE #l, #k Łączy dwa kanały plików PLAYSOUND c, s$ Odtwarza dźwięk WAV PLAYSOUNDFILE plik$ Odtwarza plik dźwiękowy PROCEDURA proc(p1, ...) PROCEDURE * RETURN RANDOMIZE [seed] Ustawia seed dla generatora liczb losowych READ var Odczytuje stałą z linii DATA RECIVE #n, t$ Odbiera wiadomość z gniazda RESTORE [etykieta] Zresetuj wskaźnik DATA lub przesuń do etykiety RETURN expr Zwraca wartość z FUNCTION RSRC_LOAD plik$ Ładuje plik RSC GEM (ATARI ST) RSRC_FREE zwalnia plik RSC GEM SEND #n, t$ Wyślij wiadomość do gniazda SENSOR ON / OFF Włącza i wyłącza czujniki SETENV t$ = a$ Ustawia zmienne środowiskowe (nie zaimplementowane) SOUND freq Pozwala głośnikowi wewnętrznemu wydać dźwięk SPLIT t$,d$,tryb,a$,b$ Dzieli t$ separatorem d$ na a$ i b$ SHELL t$ Wywołuje powłokę SPEAK t$ Mówi tekst SYSTEM t$ Wykonuje polecenie powłoki UNLINK #n Usuwa obiekt współdzielony z pamięci VOID a Oblicza wyrażenie a i zapomina o wyniku WAVE c, f, Ustaw kanały dźwiękowe dla syntezatora WORD_SEP zobacz SPLIT
Rysowanie i malowanie
BOUNDARY f Włącza lub wyłącza granice BOX x1, y1, x2, y2 Narysuj ramkę / prostokąt CIRCLE x, y, r ,, Narysuj okrąg CLIP ,,,,, Ogranicz wyjście grafiki do prostokątnego obszaru COLOR f[,b] Ustawia kolor pierwszego planu (i tła) COPYAREA ,,,,, Kopiuje prostokątny obszar CURVE ,,,,,, Narysuj krzywą Qubiana Beziera DEFFILL c, a, b Ustaw wzory wypełnienia DEFLINE a, b Ustaw szerokość i typ linii DEFMARK c, a, g Ustaw kolor, rozmiar i typ POLYMARK DEFMOUSE i Ustaw wygląd kursora myszy DEFTEXT c, s, r, g Ustaw właściwości tekstu dla LTEXT DRAW [[x1, y1] TO] x2, y2 Narysowanie linii z (x1, y1) do (x2, y2) ELLIPSE x, y, a, b [, a1, a2] Rysuje elipsę FILL x, y Obszary wypełnienia (wypełnienie powodziowe) GET x, y, w, h, g$ Zapisz część ekranu graficznego jako bitmapę w g$ GPRINT jak PRINT, ale jest wyprowadzany na ekranie graficznym GRAPHMODE tryb Ustaw tryb graficzny LINE x1, y1, x2, y2 Rysuje linię LTEXT x, y, t$ tekst grafiki liniowej PBOX x1, y1, x2, y2 Rysuje wypełniony prostokąt PCIRCLE x, y, r [, a1, a2] Rysuje wypełnione koło PELLIPSE x, y, a, b[, a1, a2] Rysuje wypełnioną elipsę PLOT x, y Narysuj punkt POLYLINE n, x(),y() Rysuje wielobok POLYFILL n, x(),y() Rysuje wypełniony wielobok (wielokąt) POLYMARK n, x(),y() Narysuj wierzchołki wieloboku PRBOX x1,y1, x2,y2 Rysuje wypełniony prostokąt z zaokrąglonymi narożnikami PUT x, y, g$ Rysuje grafikę w danej pozycji PUT_BITMAP t$, i, i, i, i Narysuj bitmapę RBOX x1, y1, x2, y2 Rysuje prostokąt z zaokrąglonymi narożnikami SCOPE a(), typ, ys, yo Szybki wykres danych SCOPE y(), x(), typ, ys, yo, xs, xo Szybki dwuwymiarowy wykres danych SETFONT f$ Ustaw zestaw znaków SETMOUSE x, y Ustaw mysz w pozycji SGET ekran$ Zapisz zawartość okna graficznego w ekran$ SPUT ekran$ Wyświetl zapisaną grafikę TEXT x, y, t$ Narysuj tekst (czcionka bitmapowa)
CLEARW [#n] Wyczyść okno graficzne CLOSEW [#n] Zamknij okno graficzne FULLW n Maksymalnie otwórz okno GET_GEOMETRY ,,,, Zwraca rozmiar i położenie okna lub ekranu GET_SCREENSIZE ,,,, Zwraca rozmiar ekranu INFOW n, t$ Ustaw linię informacyjną okna MOVEW n, x, y Przenieś okno OPENW n Otwórz okno ROOTWINDOW Rysuj w tle ekranu NOROOTWINDOW Rysuj w oknie SAVESCREEN plik$ Zapisz grafikę ekranową do pliku SAVEWINDOW plik$ Zapisz grafikę okna do pliku SCREEN n Wybierz tryb ekranu SHOWPAGE Wykonaj oczekiwaną operację graficzną SIZEW n, w, h Zmień rozmiar okna TITLEW n, t$ Ustaw tytuł okna TOPW n Przesuń okno na wierzch USEWINDOW #n Wybierz okno n dla wyjścia graficznego VSYNC Tak samo, jak SHOWPAGE
Polecenia graficznego interfejsu użytkownika
ALERT a, b$, c, d$, var[, ret$] Wyświetla okno alertu / informacji i czeka na wprowadzenie przez użytkownika EVENT ,,,,,,,, Oczekuje na reakcję użytkownika FILESELECT tyt$, ścieżka$, dflt$, f$ Wyświetla pole wyboru pliku HIDEK Ukryj wirtualną klawiaturę HIDEM Ukryj wskaźnik myszy KEYEVENT a, b Oczekuje na wydarzenie na klawiaturze LISTSELECT tyt$, list$() Wyświetla pole wyboru i czeka na wprowadzenie danych przez użytkownika MENUDEF m$(), proc Tworzy rozwijane menu MENUKILL Usuwa rozwijane menu MENUSET n, x Ustawia wartość dla pozycji menu MENU STOP Wyłącza menu rozwijane ONMENU Edytuj wpisy użytkowników dla rozwijanego menu MENU Czeka na zdarzenia w menu MOUSE x, y, k Czyta pozycję i stan myszy MOUSEEVENT ,,, Czekaj na wydarzenie myszy MOTIONEVENT ,,, Poczekaj, aż mysz się poruszy OBJC_ADD t%, o%, c% Dołącz obiekt do drzewa obiektów OBJC_DELETE t%, o% Usuwa obiekt z drzewa obiektów RSRC_LOAD plik$ Ładuje plik zasobów GEM RSRC_FREE Zwalnia plik zasobów GEM SHOWK Pokazuje wirtualną klawiaturę SHOWM Pokazuje wskaźnik myszy
Funkcje wprowadzania i wyprowadzania plików
d% = DEVICE(plik$) Zwraca identyfikator urządzenia pliku b = EOF(#n) Zwraca TRUE, jeśli wskaźnik pliku osiągnął koniec pliku b = EXIST(plik$) Zwraca TRUE, jeśli plik istnieje a = FREEFILE() Zwraca wolny numer kanału lub -1 jeśli nie jest dostępny a$ = FSFIRST$(ścieżka$,,) Wyszukuje pierwszy plik w ścieżce a$ = FSNEXT$() Wyszukuje następny plik c = INP(#n) Czyta bajt z pliku lub kanału c = INP?(#n) Określa liczbę bajtów, które można odczytać a = INP&(#n) Czyta słowo (16bit) z pliku lub kanału i = INP%(#n) Czyta długie słowo (32bit) z pliku lub kanału t$ = INPUT$(#n,num) Odczytuje num bajtów z pliku lub kanału n ret = IOCTL(#n,d%,) Wprowadza ustawienia dla pliku lub kanału. t$ = LINEINPUT$(#n) Czyta wiersz z pliku p = LOC(#n) Zwraca położenie wskaźnika pliku (-> SEEK / RELSEEK) l = LOF(#n) Zwraca długość pliku l% = SIZE(plik$) Zwraca rozmiar pliku t$ = TERMINALNAME$(#n) Zwraca nazwę terminala
Funkcje zmiennych i przetwarzania łańcuchów
adr% = ARRPTR(b()) Wskaźnik do struktury ARRAY a = ASC(t$) Zwraca kod ASCII pierwszej litery ciągu znaków b$ = BIN$(a[, n]) Konwertuje liczbę na binarną t$ = CHR$(a) Konwertuje kod ASCII na łańcuch a$ = DECLOSE$(t$) Usuwa cudzysłowy z łańcucha a = DIM?(a()) Zwraca liczbę elementów w tablicy a$ = ENCLOSE$(t$[, p$]) Obejmuje łańcuch w cudzysłowy f = GLOB(a$, b$[, flagi]) TRUE jeśli a$ odpowiada wzorowi w b$ t$ = HEX$(a[, n]) Konwertuje liczbę na liczbę szesnastkową t$ = INLINE$(a$) Konwersja z 6-bitowego ASCII do 8-bitowego binarnego a = INSTR(s1$, s2$[, n]) Zwraca TRUE, jeśli s2$ jest zawarte w s1$ a = TALLY(t$, s$) Zwraca liczbę wystąpień s$ w t$ b% = INT(a) Konwertuje na liczbę całkowitą (integer) t$ = LEFT$(a$[,n]) Zwraca lewe n bajtów ciągu a$ t$ = LEFTOF$(a$, b$) Zwraca lewą część ciągu a$ oddzielone przez b$ l = LEN(t$) Zwraca długość ciągu znaków u$ = LOWER$(t$) Konwertuje ciąg znaków na małe litery l = LTEXTLEN(t$) Zwraca szerokość LTEXT w pikselach m$ = MID$(t$, s[, l]) Zwraca sekcję ciągu t$ z pozycji s o długości l t$ = MKA$(a()) Konwertuje całą tablicę na ciąg znaków t$ = MKI$(i) Konwertuje (16bit) liczbę całkowitą na ciąg 2-bajtowy t$ = MKL$(i) Konwertuje (32bit) liczbę całkowitą na ciąg 4-bajtowy t$ = MKF$(a) Konwertuje liczbę zmiennoprzecinkową na ciąg 4-bajtowy t$ = MKD$(a) Konwertuje liczbę zmiennoprzecinkową na ciąg 8-bajtowy o$ = OCT$(d, n) Konwertuje liczbę całkowitą d na ciąg liczby ósemkowej t$ = REPLACE$(a$, s$, r$) Zamień s$ na r$ w a$ t$ = REVERSE$(a$) Zwraca odwrotność ciągu znaków t$ = RIGHT$(a$[,n]) Zwraca prawe n znaków a$ t$ = RIGHTOF$(a$, b$) Zwraca prawą część a$ przedzieloną b$ a = RINSTR(s1$, s2$[,n]) Testuje od prawej, czy s2$ jest zawarte w s1$ t$ = SPACE$(i) Zwraca ciąg i znaków spacji t$ = STR$(a[,b,c]) Konwertuje liczbę na łańcuch t$ = STRING$(i,w$) Zwraca ciąg składający się z i kopii w$ u$ = TRIM$(t$) Przycinanie t$ u$ = XTRIM$(t$) Przycinanie t$ u$ = UCASE$(t$) Konwertuje t$ na wielkie litery u$ = UPPER$(t$) Konwertuje t$ na wielkie litery u$ = USING$(a, f$) formatuje reprezentację liczbową a = VAL(t$) konwertuje ciąg na liczbę, jeśli to możliwe i = VAL?(t$) Zwraca liczbę znaków, które można przekonwertować na liczbę adr% = VARPTR(v) Zwraca wskaźnik do zmiennej u$ = WORD$(b$, n) Zwraca n-ty wyraz b$ e = WORT_SEP(t$, d$, m, a$, b$) Dzieli t$ na części
b$ = ARID$(a$) Adaptacyjne dekodowanie arytmetyczne rzędu 0 b$ = ARIE$(a$) Adaptacyjne kodowanie arytmetyczne rzędu 0 b$ = BWTD$(a$) Dekoduje przez transformatę odwrotną Burrowsa-Wheelera b$ = BWTE$(a$) Stosuje transformatę Burrowsa-Wheelera na a$ c$ = COMPRESS$(a$) Wykonuje kompresję bezstratną na zawartości napisów c$ = UNCOMPRESS$(a$) Wykonuje bezstratną dekompresję c% = CRC(t$[, oc]) Zwraca 32-bitowe sumy kontrolne e$ = ENCRYPT$(t$, key$) Szyfruje wiadomość kluczem key$ t$ = DECRYPT$(e$, key$) Odszyfrowuje wiadomość kluczem key$ b$ = MTFD$(a$) Dekodowanie "Przenieś na wierzch" b$ = MTFE$(a$) Kodowanie "Przenieś na wierzch" b() = CVA(a$) Rekonstruuje tablicę z ciągu znaków b% = CVI(a$) Konwertuje 2-bajtowy ciąg znaków na liczbę b% = CVL(a$) Konwertuje 4-bajtowy ciąg znaków na liczbę b = CVS(a$) Konwertuje ciąg 4-bajtowy na liczbę zmiennoprzecinkową b = CVF(a$) Konwertuje ciąg 4-bajtowy na liczbę zmiennoprzecinkową b = CVD(a$) Konwertuje ciąg 8-bajtowy na liczbę zmiennoprzecinkową t$ = INLINE$(a$) Konwertuje 6-bitowe ASCII na 8-bitowy kod binarny t$ = REVERSE$(a$) Odwraca łańcuch b$ = RLD$(a$) "Run length decoding" b$ = RLE$(a$) "Run length encoding"
adr% = ARRPTR(b()) Wskaźnik do struktury ARRAY
i% = DPEEK(adr%) Czyta słowo od wskaźnika adr%
b% = LPEEK(adr%) Odczytuje long (4 bajty) z adresu
adr% = MALLOC(n%) Przydziela rozmiar bajtów pamięci
adr% = MSHRINK(adr%, n%) Zmniejsza rozmiar obszaru pamięci
d% = PEEK(a%) Odczytuje bajt z adresu a%
adr% = REALLOC(oadr%, n%) Zmienia rozmiar obszaru pamięci
adr% = SHM_ATTACH(id) Dołącza segment pamięci współdzielonej
id = SHM_MALLOC(size, key) Zwraca id. segmentu pamięci współużytkowanej
adr% = SYM_ADR(#n, s$) Zwraca wskaźnik do symbolu z pliku obiektu
współdzielonego
adr% = VARPTR(v) Wskaźnik do zmiennej w pamięci
c% = AND(a%, b%) Jak c = (a AND b) c% = OR(a%, b%) Jak c = (a OR b) c% = XOR(a%, b%) Jak c = (a XOR b) c% = EQV(a%, b%) Jak c = (EQV b) c% = IMP(a%, b%) Jak c = (a IMP b) b% = BCHG(x%, bit%) Zmienia bit w x% z 0 na 1 lub z 1 na 0 b% = BCLR(x%, bit%) Ustawia bit w x% na zero. b% = BSET(x%, bit%) Ustawia bit w x% na 1. b% = BTST(x%, bit%) Zwraca -1, jeśli bit w x% wynosi 1. b% = BYTE(x%) Jak b = x AND 255 b% = CARD(x%) Jak b = x AND 0xffff b% = WORD(x%) Jak b = x AND 0xffff b% = EVEN(d) Zwraca TRUE, jeśli d jest parzyste b% = ODD(d) Zwraca TRUE, jeśli d jest nieparzyste b% = GRAY(a) Kod Graya. Jeśli a<0: odwrotność kodu Graya. b% = SHL(a) Przesuń bity w lewo b% = SHR(a) Przesuń bity w prawo b% = SWAP(a) Zamienia wysokie i niskie słowa w a
Biblioteka funkcji matematycznych zawiera kompleksowy zestaw funkcji matematycznych, w tym:
trygonometryczny
arc-trygonometryczny
hiperboliczny
arc-hiperboliczny
logarytmiczny (bazy e i bazy 10)
wykładniczy (bazy e i bazy 10)
Różne (pierwiastek kwadratowy, potęga itp.)
Niektóre funkcje matematyczne są zdefiniowane na wektorach i macierzach.
b = ABS(a) Podaje wartość bezwzględną, b = | a | c = ADD(a, b) Jak c = a + b b = CBRT(a) pierwiastek sześcienny z a a = CEIL(b) Odcięcie miejsc dziesiętnych a = CINT(b) Obetnij ułamki dziesiętne (Uwaga: różne do INT() !) z = COMBIN(n, k) Liczba kombinacji n po k, z = n!/(n-k)!*k! c = DIV(a, b) Jak c = a / b b() = FFT(a()[, f%]) Dyskretna transformata Fouriera macierzy a = FIX(b) Zaokrąglij liczbę do najbliższej liczby całkowitej a = FLOOR(b) Zaokrąglij liczbę w dół b = FRAC(a) Zwraca część część ułamkową liczby y = GAMMA(x) Funkcja gamma y = LGAMMA(x) Logarytm funkcji gamma a = HYPOT(x,y) Moduł wektora [x,y], a=SQRT(x^2+y^2) b = INT(a) Konwertuje liczbę na liczbę całkowitą b() = INV(a()) Oblicz odwrotność macierzy kwadratowej i = SGN(a) Zwraca znak (-1,0,1) b = SQR (a) Pierwiastek kwadratowy b = SQRT(a) Pierwiastek kwadratowy b = TRUNC(a) Odcina miejsca dziesiętne b = LN(a) Logarytm naturalny (podstawa e) b = LOG(a) Logarytm naturalny (podstawa e) b = LOG10(a) Logarytm (podstawa 10) b = LOGB(x) Logarytm podstawy 2 b = LOG1P(x) Jak b = log(1 + x), najwyższa precyzja przy zerze c = MOD(a, b) Jak c = (a MOD b) c = MUL(a, b) Jak c = a * b b = EXP(a) Funkcja wykładnicza, b = e^a b = EXPM1(a) Funkcja wykładnicza minus jeden, b = EXP(a)-1 b = FACT(a) Silnia, b = a! a = PRED(x) Zwraca poprzednią liczbę całkowitą dla x a = SUCC(x) Zwraca następną większą liczbę całkowitą od x b() = SOLVE(a(), x()) Rozwiązuje liniowy układ równań z = VARIAT(n, k) Liczba permutacji n elementów
Kąty są zawsze radianami, zarówno dla argumentów, jak i wartości zwracanych.
b = RAD(a) Konwertuje stopnie na radiany b = DEG(a) Konwertuje radiany na stopnie
b = SIN(a) Sinus b = COS(a) Cosinus b = TAN(a) Tangens b = ASIN(a) Arcus sinus b = ACOS(a) Arcus cosinus b = ATAN(a) Arcus tangens b = ATN(a) Arcus tangens b = ATAN2(a,c) Rozszerzony arcus tangens b = SINH(a) Sinus hiperboliczny b = COSH(a) Cosinus hiperboliczny b = TANH(a) Tangens hiperboliczny b = ASINH(a) Hiperboliczny arcus sinus b = ACOSH(a) Hiperboliczny arcus cosinus b = ATANH(a) Hiperboliczny arcus tangens
a = GASDEV(sztuczna) Zwraca losową liczbę rozkładu Gaussa a = RAND(sztuczna) Zwraca całkowitą liczbę losową a = RANDOM(n) Zwraca całk. liczbę losową z przedziału od 0 do n a = RND(sztuczna) Zwraca losową liczbę od 0 do 1 a = SRAND(seed) Jak RANDOMIZE
ret% = CALL(adr%[, par]) Wywołuje kod maszynowy lub funkcję C t$ = ENV$(n$) Zwraca wartość zmiennej środowiskowej n$ t$ = ERR$(i) Zwraca komunikat o błędzie numer i ret = EXEC(adr[, var]) Zobacz polecenie EXEC, zwraca int i% = FORK() Tworzy proces potomny d$ = JULDATE$(a) Zwraca date$ z juliańskiego dnia a a = JULIAN(data$) Zwraca datę kalendarza juliańskiego a$ = PARAM$(i) Zwraca i-te słowo parametrów wiersza poleceń t$ = PRG$(i) Linia programu a = SENSOR(i) Zwraca wartość i-tego czujnika t$ = SYSTEM$(n$) Wykonaj polecenie n$ powłoki t$ = UNIXTIME$(i) Podaje czas time$ z TIMER'a d$ = UNIXDATE$(i) Podaje datę date$ z TIMER'a
c = COLOR_RGB(r,g,b[,a]) Pobiera nr koloru z wartości rgb(a). a = EVENT?(maska%) Zwraca TRUE, jeśli oczekuje na zdarzenie graficzne a = FORM_ALERT(n, t$) Okno komunikatu z domyślnym przyciskiem n ~FORM_CENTER(adr%, x, y, w, h) Centruje drzewo obiektów na ekranie a = FORM_DIAL(,,,,,,,,) Złożona funkcja przygotowania ekranu a = FORM_DO(i) Wykonaj dialog c = GET_COLOR(r, g, b) Pobiera nr koloru z wartości rgb. d = OBJC_DRAW(,,,,) Rysuj drzewo obiektów ob = OBJC_FIND(drzewo, x, y) Zwraca numer obiektu o danych współrzędnych a = OBJC_OFFSET(t%, o, x, y) Oblicza bezwzględne współrzędne obiektu c = POINT(x, y) Zwraca koloru punktu grafiki w bieżącym oknie c = PTST(x, y) Zwraca koloru punktu grafiki w bieżącym oknie a = RSRC_GADDR(typ, no) Zwraca wskaźnik do drzewa obiektów
a = EVAL(t$) Oblicza wyrażenie w t$ m = MAX(a, b, c, ...) Zwraca największą wartość m = MAX(f()) Zwraca największą wartość m = MIN(a, b, c, ...) Zwraca najmniejszą wartość m = MIN(array()) Zwraca najmniejszą wartość m = MIN(funkcja()) Jeszcze nie zaimplementowana
X11-Basic może wytworzyć pewną liczbę błędów wewnętrznych, do których odnosi się liczba (ERR, patrz również ERROR).
Znaczenie tych błędów i ich wyrażenie tekstowe jest następujące:
0 Dzielenie przez 0 1 Przepełnienie 2 Wartość nie jest liczbą całkowitą -2147483648 .. 2147483647 3 Wartość nie jest bajtem 0 ... 255 4 Wartość nie jest słowem -32768 .. 32767 5 Pierwiastek kwadratowy tylko dla liczb dodatnich 6 Logarytm tylko dla liczb większych od zera 7 Nieznany błąd 8 Brak pamięci 9 Funkcja lub polecenie nie jest zaimplementowane w tej wersji 10 Ciąg za długi 11 Argument musi być dodatni 12 Program za długi, pamięć pełna -> NEW 13 Niewłaściwe typy w wyrażeniu 14 Tablica wymiarowana dwukrotnie 15 Tablica nie jest zwymiarowana 16 Indeks pola jest zbyt duży 17 Dim za duży 18 Niewłaściwa liczba indeksów 19 Nie znaleziono procedury 20 Nie znaleziono etykiety 21 Dla Open dozwolone tylko: "I"nput "O"utput "A"ppend "U"pdate 22 Plik już otwarty 23 Błędny plik 24 Plik nie jest otwarty 25 Błędny wpis, brak numeru 26 Koniec pliku - EOF 27 Zbyt wiele punktów dla Polyline / Polyfill 28 Tablica musi być jednowymiarowa 29 Nieprawidłowy adres! 30 Merge - Brak pliku ASCII 31 Merge - linia zbyt długa - ANULUJ 32 ==> Składnia niepoprawna 33 Etykieta nie została zdefiniowana 34 Za mało danych 35 Dane nie numeryczne 36 Struktura programu niepoprawna 37 Dyskietka / dysk twardy pełny 38 Polecenie niemożliwe w trybie bezpośrednim 39 Nie jest możliwy Gosub 40 CLEAR niemożliwe w pętlach For-Next lub procedurach 41 CONT nie jest możliwe 42 Zbyt mało parametrów 43 Wyrażenie zbyt złożone 44 Funkcja nie została zdefiniowana 45 Zbyt wiele parametrów 46 Nieprawidłowy parametr, musi być liczbą 47 Nieprawidłowy parametr, musi być łańcuchem 48 Open "R" - błędna długość rekordu 49 Zbyt wiele plików "R" (maks. 31) 50 Brak pliku "R" 51 Analizator składni: Błąd składni <> 52 Pole większe niż długość rekordu 53 Nieprawidłowy format graficzny 54 GET / PUT: długość łańcucha pola jest nieprawidłowa 55 Błędny numer bloku GET / PUT 56 Nieprawidłowa liczba parametrów 57 Zmienna jeszcze nie zainicjowana 58 Zmienna jest niewłaściwego typu 59 Grafika ma nieprawidłową głębię kolorów 60 Niepoprawna długość łańcucha duszka 61 Błąd w RESERVE 62 Menu jest nieprawidłowe 63 RESERVE jest nieprawidłowe 64 Nieprawidłowy wskaźnik 65 Rozmiar pola <256 66 Brak tablicy VAR 67 ASIN / ACOS nieprawidłowe 68 Zły typ VAR 69 ENDFUNC bez RETURN 70 Nieznany błąd 70 71 Indeks zbyt duży 72 Błąd w RSRC_LOAD 73 Błąd w RSRC_FREE 74 Niezgodność wymiarowania macierzy 75 Przepełnienie stosu! 76 Nielegalna nazwa zmiennej. 77 Funkcja nie została zdefiniowana dla liczb zespolonych. 78 Nieprawidłowy parametr, musi być tablicą 80 Operacje matrycowe dozwolone tylko dla macierzy jedno- lub dwuwymiarowych 81 Matryce nie mają tej samej kolejności 82 Nie zdefiniowano produktu wektorowego 83 Nie zdefiniowano produktu macierzy 84 Nie zdefiniowano produktu skalarnego 85 Transpozycja tylko w przypadku macierzy dwuwymiarowych 86 Macierz musi być kwadratowa 87 Nie zdefiniowano transpozycji 88 Nie zdefiniowano FACT / COMBIN / VARIAT / ROOT 89 Tablica musi być dwuwymiarowa 90 Błąd w Local 91 Błąd w For 92 Resume (next) nie możliwe: Fatal, For lub Local 93 Błąd stosu 94 Parametry muszą być ARRAY l. rzeczywistych 95 Parametr musi być ARRAY 96 ARRAY ma niewłaściwy typ. Nie można przekonwertować. 97 Ta operacja nie jest dozwolona w oknie głównym 98 Niedozwolony numer okna (0-16) 99 Okno nie istnieje 100 X11-BASIC Wersja 1.25 Prawa autorskie (c) 1997-2018 Markus Hoffmann 101 ** 1 - Naruszenie ochrony pamięci 102 ** 2 - Błąd magistrali: peek / poke? 103 ** 3 - Błąd adresu: Dpoke / Dpeek, Lpoke / Lpeek? 104 ** 4 - Nielegalna instrukcja 105 ** 5 - Dzielenie przez zero 106 ** 6 - Wyjątek CHK 107 ** 7 - Wyjątek TRAPV 108 ** 8 - Naruszenie uprawnień 109 ** 9 - Wyjątek śledzenia 110 ** 10 - Zerwana rura: Przerwano przekazywanie wyników 131 * Liczba kolizji przekracza maksymalną wartość licznika. 132 * Zły typ medium 133 * Nie znaleziono nośnika 134 * Przekroczono limit 135 * Błąd zdalnego wejścia / wyjścia 136 * Jest plikiem nazwy typów 137 * Brak semafora XENIX 138 * Nie jest plikiem nazwy typów XENIX 139 * Struktura wymaga czyszczenia 140 * Uchwyt pliku Stale NFS 141 * Operacja jest teraz w toku 142 * Operacja już trwa 143 * Brak trasy do hosta 144 * Host jest wyłączony 145 * Połączenie odrzucone 146 * Przekroczono limit czasu połączenia 147 * Zbyt wiele odniesień: nie można złączyć 148 * Nie można wysłać po zamknięciu punktu końcowego transportu 149 * Transportowy punkt końcowy nie jest podłączony 150 * Punkt końcowy transportu jest już podłączony 151 * Brak dostępnej przestrzeni buforowej 152 * Resetowanie połączenia przez peer 153 * Oprogramowanie spowodowało przerwanie połączenia 154 * Połączenie sieciowe przerwane z powodu zresetowania 155 * Sieć jest nieosiągalna 156 * Sieć nie działa 157 * Nie można przypisać żądanego adresu 158 * Adres już w użyciu 159 * Rodzina adresów nieobsługiwana przez protokół 160 * Rodzina protokołów nie jest obsługiwana 161 * Operacja nie jest obsługiwana w punkcie końcowym transportu 162 * Typ gniazda nie jest obsługiwany 163 * Protokół nie jest obsługiwany 164 * Protokół jest niedostępny 165 * Protokół nieprawidłowego typu dla gniazda 166 * Wiadomość zbyt długo 167 * Wymagany adres docelowy 168 * Obsługa gniazda w nie-gnieździe 169 * Zbyt wielu użytkowników 170 * Błąd rury potoku 171 * Przerwane wywołanie systemowe powinno zostać ponownie uruchomione 172 * Nielegalna sekwencja bajtów 173 * Nie można bezpośrednio wykonać udostępnionej biblioteki 174 * Próba połączenia z wieloma bibliotekami współdzielonymi 175 * Sekcja .lib w a.out jest uszkodzona 176 * Uzyskiwanie dostępu do uszkodzonej biblioteki współużytkowanej 177 * Nie można uzyskać dostępu do udostępnionej biblioteki 178 * Zmieniono adres zdalny 179 * Deskryptor pliku w złym stanie 180 * Nazwa nie jest unikalna w sieci 181 * Zbyt duża wartość dla zdefiniowanego typu danych 182 * Nie jest to wiadomość danych 183 * Błąd specyficzny dla RFS 184 * Spróbuj ponownie 185 * Za dużo napotkanych dowiązań symbolicznych 186 * Nazwa pliku jest za długa 187 * Wystąpiłoby zakleszczenie zasobów 188 * Błąd propagacji 189 * Błąd strony pamięci 190 * Brak pliku wykonywalnego 191 * Link został przerwany 192 * Obiekt jest zdalny 193 * Nie można przedstawić wyniku matematycznego 194 * Argument spoza dziedziny funkcji 195 * Łącze między różnymi urządzeniami 196 * Urządzenie nie jest strumieniem 197 * Montowanie urządzenia zajętego 198 * Wymagane urządzenie blokowe 199 * Zły adres 200 * Brak procesów 201 * Brak dzieci 202 * Wymiana pełna 203 * Wywołanie przerwania systemowego 204 * Błędna wymiana 205 * Odmowa uprawnień, musisz być superużytkownikiem 206 * Operacja na tym kanale nie jest możliwa (więcej) 207 * Brak więcej plików 208 * Numer połączenia poza zakresem 209 * Resetowanie poziomu 3 210 * Niedozwolony identyfikator napędu 211 * Poziom 2 niezsynchronizowany 212 * Numer kanału poza zakresem 213 * Identyfikator usunięty 214 * Brak komunikatu o żądanym typie 215 * Operacja zostanie zablokowana 216 * Nieprawidłowy adres strony 217 * Katalog nie jest pusty 218 * Funkcja nie zaimplementowana 219 * Nielegalny uchwyt 220 * Dostęp niemożliwy 221 * Zbyt wiele otwartych plików 222 * Ścieżka nie znaleziona 223 * Nie znaleziono pliku 224 * Zerwana rura 225 * Za dużo połączeń 226 * System plików tylko do odczytu 227 * Nielegalne przeszukiwanie 228 * Brak miejsca na urządzeniu 229 * Plik jest zbyt duży 230 * Plik tekstowy zajęty 231 * Nie jest to maszyna do pisania 232 * Zbyt wiele otwartych plików 233 * Przepełnienie tabeli plików 234 * Nieprawidłowy argument 235 * Jest katalogiem 236 * Nie jest katalogiem 237 * Brak takiego urządzenia 238 * Łącze między różnymi urządzeniami 239 * Plik istnieje 240 * Zły sektor (sprawdzenie) 241 * Nieznane urządzenie 242 * Dysk został zmieniony 243 * Odmowa pozwolenia 244 * Za mało pamięci głównej 245 * Błąd odczytu 246 * Błąd zapisu 247 * Brak papieru 248 * Nie znaleziono sektora 249 * Lista Arg zbyt długa 250 * Błąd wyszukiwania 251 * Złe żądanie 252 * Błąd CRC: błąd sumy kontrolnej dysku 253 * Nie ma takiego procesu 254 * Limit czasu przekroczony 255 * Ogólny błąd wejścia / wyjścia
Dokładny opis komend X11 Basic jest dostępny w oryginalnej angielskiej instrukcji.
Efektywne programowanie
W tej części przedstawię kilka wskazówek jak tworzyć efektywne, czyli szybkie programy. Zagadnienie szybkości działania algorytmów opisuje teoria złożoności obliczeniowej. Zawiera ona jednak luki, nieścisłości, czy wręcz sprzeczności. W szczególności całkowicie pomija ona kwestię jakości implementacji konkretnego algorytmu, która wg mnie jest równie ważna jak jakość algorytmów, dlatego tym się tutaj zajmiemy.
Luki w teorii złożoności obliczeniowej
Analizując artykuł „Złożoność obliczeniowa” z polskiej Wikipedii postaram się wykazać wady tej teorii.
Zacznijmy od założeń. Czasową złożoność obliczeniową algorytmu określa się jako liczbę operacji podstawowych (dominujących). Jednak teoria nie precyzuje czym dokładnie są te operacje. Powinny one być niezależne od maszyny, na której algorytm będzie wykonywany, czy języka programowania. W tym celu stosuje się tzw. abstrakcyjne modele obliczeń, ale jeśli są one dość ściśle zdefiniowane, to wg mnie nie są abstrakcyjne, lecz modelują konkretną maszynę. W praktyce - albo intuicyjnie pewne operacje uważa się za podstawowe, albo całą zawartość głównej pętli algorytmu traktuje się jak pojedynczą operację dominującą. Jednak pętla ta może zawierać instrukcje złożone, których złożoność obliczeniowa też może być różna, właśnie w zależności od maszyny, można więc powiedzieć, że w pewnych przypadkach teoria ta jest wewnętrznie sprzeczna. Teoretyczna analiza takich przypadków może być bardzo trudna.
Ponadto zazwyczaj złożoność czasową określa się jako funkcję zależną od tylko jednego parametru charakteryzującego rozmiar danych wejściowych, np. ilość wprowadzonych liczb, podczas gdy w rzeczywistości znaczenie może mieć też jak duże są to liczby, co zwykle jest w teorii pomijane. Zakłada się też, że obliczenia będą prowadzone na dużej ilości danych wejściowych, podczas gdy w praktyce często potrzebujemy wykonać obliczenia dla wielu zestawów danych, które jednak nie muszą duże, wtedy szybszy może okazać się prostszy algorytm o teoretycznie większej złożoności czasowej.
Wikipedia podaje:
„Pomiar rzeczywistego czasu zegarowego jest mało użyteczny ze względu na silną zależność od sposobu realizacji algorytmu, użytego kompilatora oraz maszyny, na której algorytm wykonujemy.”
Ale przecież w praktyce właśnie istotny jest czas rzeczywisty, nie teoretyczny, a wykonując kilka pomiarów na tej samej maszynie możemy określić funkcję szacującą czas wykonania w zależności od wielkości danych wejściowych. Poza tym obecnie większość komputerów i języków programowania działa na podobnej zasadzie. Dlatego w dalszej części podam przykłady jak można optymalizować algorytm pod tym kątem. Po części pokazany zostanie też wpływ maszyny oraz języka (jego kompilatora).
Przykłady optymalizacji czasowej
Generalnie zwiększenie szybkości działania możemy uzyskać na dwa sposoby:
Zastąpienie komend ich szybszymi odpowiednikami
Zredukowanie ilości komend
Jako przykład posłuży program generujący ciągi Fibonacciego w językach X11-Basic oraz GFA-BASIC 32 pod systemem Windows 7. Jest to typowy przykład tzw. programowania dynamicznego, którym zastępujemy rekurencję. Oto kod w X11-Basic:
c = Timer For t = 1 To 1000 For i = 0 To 45 f = @fibo(i) Next Next t c = Timer - c Print "czas: ";c, "fibo(45)=";f End Function fibo(n%) If (n% = 0) Or (n% = 1) Return n% EndIf a% = 1 b% = 1 For i% = 3 To n% c% = a% a% = b% b% = c% b% = b%+a% Next Return b% EndFunction
Program generuje 1000 razy ciągi Fibonacciego od 0 do 45 (razem 46000 ciągów). Operuje na zmiennych całkowitych 32-bitowych. Czas wykonania w X11-Basic: 10 sekund, w GFA-BASIC 100000 iteracji wykonuje się w 3 sekundy.
Dzięki drobnej sztuczce polegającej generalnie na zmianie kolejności działań pozbywamy się jednego podstawienia w pętli. Poprawiona funkcja wygląda tak:
Function fibo(n%) If (n% = 0) Or (n% = 1) Return n% EndIf a% = 1 b% = 1 c% = 1 For i% = 3 To n% c% = c% + a% a% = b% b% = c% Next Return b% EndFunction
W efekcie czas wykonania w GFA BASIC skraca się do 2 sekund, jednak w X11 nie widać różnicy. Wygląda na to, że większość czasu „pożera” interpreter, więc porównywać będziemy programy skompilowane. Po skompilowaniu i zwiększeniu liczby iteracji do 10000 program w pierwszej wersji wykonuje się w czasie 6.5 sekundy, a poprawiony 5.5 sek.
Naturalnym pomysłem wydaje się użycie komendy zamieniającej wartości zmiennych, jeśli taka istnieje w danym języku. W naszym przypadku jest to komenda SWAP a%, b%. W GFA-BASIC powoduje to skrócenie czasu wykonywania również do 2 sekund. Jednak w X11-Basic czas ulega wydłużeniu i to aż do 12 sekund. Ponadto komenda ta może nie działać ze wszystkimi typami zmiennych, np. w GFA-BASIC nie działa z Int64.
Kolejnym pomysłem jest zastosowanie tablic oraz operacji bitowej AND 1 lub MOD 2, które dają tutaj ten sam wynik:
Function fibo(n%) If (n% = 0) Or (n% = 1) Return n% EndIf Dim f%(2) f%(0) = 1 f%(1) = 1 c% = 1 For i% = 3 To n% c% = c% + f%(i% and 1) f%(i% and 1) = c% Next Return f%((i% - 1) And 1) EndFunction
Jednak w tym wypadku czas wykonania okazał się dłuższy i wyniósł odpowiednio 19 i 6 sekund. Jest to prawdopodobnie głównie spowodowane dłuższym wykonywaniem operacji na tablicach w porównaniu do pojedynczych zmiennych.
Dzięki operacji XOR możemy pozbyć się jeszcze jednej linii, wtedy zawartość pętli FOR wygląda tak:
f%(i% and 1) = f%(i% and 1) + f%((i% Xor 1) and 1)XOR 1 powoduję zmianę ostatniego bitu, a AND 1 wyzerowanie pozostałych. Powoduje to jednak wydłużenie czasu odpowiednio do 25 i 7 sekund. W GFA-BASIC możemy to trochę przyspieszyć stosując w podstawieniu formulę +=, która zwiększa zmienną o daną wartość, wtedy czas wykonania znów wyniesie 6 sekund (uwaga – operacja ta może się czasem inaczej zachowywać niż standardowe dodawanie i podstawienie).
Wróćmy do pierwotnej wersji i pozbądźmy się zmiennej c. Zawartość pętli wygląda tak:
b% = b% + a% a% = b% - a%
Zamiast 3 podstawień i dodawania mamy 2 podstawienia, dodawanie i odejmowanie. W X11-Basic skutkuje to minimalnym wydłużeniem czasu, a w GFA-BASIC skróceniem.
Czy można więc jeszcze zmniejszyć ilość wykonywanych operacji ? Okazuje się, że tak. Możemy przecież wykonywać 2 kroki w jednym przebiegu pętli:
Function fibo(n%) If n% <= 2 Return (n%=0) + 1 EndIf a% = 1 - (n% Mod 2) b% = 1 For i% = a%+2 To n% Step 2 a% = a% + b% b% = b% + a% Next Return b% EndFunction
W efekcie czas wykonywania skraca się do 4.5 sek. dla X11-Basic i do 2 sek. dla GFA-BASIC, a stosując operator += do ok. 1 sek. Odpowiednikiem += w X11-Basic jest operacja ADD, ale jej zastosowanie, zamiast skrócić, wydłużyło czas wykonywania aż do 11 sekund !
Jak widać udało się uzyskać znaczne przyspieszenie. Optymalizacja szczególnie opłacalna jest w przypadku GFA-BASIC gdzie przyspieszenie wyniosło prawie 300%, a przecież wersja początkowa już była bardzo prosta, zawierała zaledwie 5 operacji w pętli.
Zauważyłeś, że poprzednie wersje funkcji podają błędny wynik dla wartości 2 ? Dzieje się tak ponieważ w X11-Basic zawartość pętli typu FOR i=a TO b wykonuje się 1 raz w przypadku gdy a>b. Pętla taka nie jest wykonywana w GFA-BASIC. Dlatego wprowadziłem poprawkę w ostatniej wersji na początku funkcji i wynik jest natychmiast zwracany dla n%<=2. Przypominam, ze prawda (TRUE) w X11-Basic ma wartość -1. W porównaniu z GFA-BASIC inna jest też kolejność wykonywania działań w wyrażeniu 1 – (n% Mod 2), dlatego konieczne było użycie nawiasu. Resztę kodu pozostawiam do samodzielnej analizy.
Nasuwa się pytanie jak dokładnie policzyć złożoność czasową tych algorytmów. Liczyć ilość przebiegów pętli, czy operacji ? Jeśli operacji, to wszystkich, czy jakichś szczególnych ?
Wypróbujmy teraz inny algorytm wykorzystujący pewne „macierzowe” właściwości liczb Fibonacciego oraz metodę szybkiego potęgowania działający w tzw. czasie logarytmicznym:
Function fibo(n%) If n% <= 2 Return (n%=0) + 1 EndIf ' ustawiamy macierz Q q11% = 1 q12% = 1 q21% = 1 q22% = 0 ' w macierzy W tworzymy macierz jednostkowš w11% = 1 w12% = 0 w21% = 0 w22% = 1 n% = n%-1 ! będzie nam potrzebna n-1 potęga Q Do While n% If (n% And 1) = 1 ' wykonujemy mnożenie P = W x Q p11% = w11% * q11% + w12% * q21% p12% = w11% * q12% + w12% * q22% p21% = w21% * q11% + w22% * q21% p22% = w21% * q12% + w22% * q22% ' wynik przenosimy: W = P w11% = p11% w12% = p12% w21% = p21% w22% = p22% EndIf n% = Shr(n%,1) ! usuwamy z n sprawdzony bit If n% = 0 Exit Do EndIf ' podnosimy Q do kwadratu: P = Q x Q p11% = q11% * q11% + q12% * q21% p12% = q11% * q12% + q12% * q22% p21% = q21% * q11% + q22% * q21% p22% = q21% * q12% + q22% * q22% ' wynik przenosimy: Q = p q11% = p11% q12% = p12% q21% = p21% q22% = p22% Loop Return w11% EndFunction
Wynik: 5.3 i 2 sekundy, czyli dłużej niż poprzedni algorytm działający przecież w czasie liniowym... Dzieje się tak, ponieważ liczymy tylko do 45. liczby Fibonacciego, a przy małych danych wejściowych często właśnie lepiej sprawdzają się prostsze algorytmy pomimo teoretycznie większej złożoności czasowej.
A tak wygląda funkcja wykorzystująca operacje mnożenia macierzy wbudowane w X11-Basic:
Function fibo(n%) If n% <= 2 Return (n%=0) + 1 EndIf ' ustawiamy macierz Q q%() = [1,1;1,0] ' w macierzy W tworzymy macierz jednostkowš w%() = [1,0;0,1] n% = n%-1 ! będzie nam potrzebna n-1 potęga Q Do While n% If (n% And 1) = 1 ' wykonujemy mnożenie W = W x Q w%()=w%()*q%() EndIf n% = Shr(n%,1) ! usuwamy z n sprawdzony bit If n% = 0 Exit Do EndIf ' podnosimy Q do kwadratu: Q = Q x Q q%()=q%()*q%() Loop Return w%(0,0) EndFunction
Kod wygląda ładnie, ale czas: 6.2 sek. Znów przyczyną spowolnienia są zapewne tablice. Do tego po skompilowaniu program zwraca błędny wynik...
Spróbujmy zoptymalizować poprzednią wersję:
Function fibo(n%) If n% <= 2 Return (n%=0) + 1 EndIf q1% = 1 q2% = 1 q3% = 0 w1% = 1 w2% = 1 w3% = 0 n% = n%-2 ! będzie nam potrzebna n-2 potęga Q Do While n% If (n% And 1) = 1 w3% = w2% * q2% + w3% * q3% p1% = w1% * q1% + w2% * q2% w2% = w1% * q2% + w2% * q3% w1% = p1% EndIf n% = Shr(n%,1) ! usuwamy z n sprawdzony bit If n% = 0 Exit Do EndIf t% = q2% * q2% q2% = q2% * (q1% + q3%) q1% = q1% * q1% + t% q3% = q3% * q3% + t% Loop Return w1% EndFunction
Czas: 4 i 2 sekundy. Oprócz pozbycia się nadmiarowych działań wprowadzona została dodatkowa zmienna t do zapamiętania wyniku działania, które się powtarza, choć, jeśli działania są proste, a powtórzeń mało, może to być nieopłacalne. Najlepiej jeśli jakieś obliczenia da się wykonać poza pętlą. Można też wykorzystać tablicę do zapamiętywania wielu wyników, np. jeśli wielokrotnie musimy użyć liczb Fibonacciego z jakiegoś stosunkowo niewielkiego zakresu, to wystarczy je raz obliczyć, zapamiętać w tablicy i później tylko z niej odczytywać.
A to już głębsza modyfikacja, którą pozostawiam do samodzielnej analizy:
Function fibo(n%) If n% <= 2 Return (n%=0) + 1 EndIf n% = n%-1 ! będzie nam potrzebna n-1 potęga Q a$ = Bin$(n%) l% = Len(a$)-1 a$ = Right$(a$,l%) q1% = 1 q2% = 1 q3% = 0 For i% = 1 To l% t% = q2% * q2% q2% = q2% * (q1% + q3%) q1% = q1% * q1% + t% q3% = q3% * q3% + t% If Mid$(a$, i%, 1) = "1" q3% = q2% q2% = q1% q1% = q2% + q3% EndIf Next Return q1% EndFunction
Pomimo zmniejszenia liczby kroków pętli i uproszczeniu rachunków czas się zwiększył do 6 i 5 sek. Doszły nam operacje na łańcuchach, więc możemy to podejrzewać o przyczynę spowolnienia. Możliwe też, że pętla FOR działa wolniej niż WHILE. Warto też odnotować różnicę w działaniu funkcji MID$, która w GFA-BASIC przy pominięciu ostatniego parametru zwraca wszystkie pozostałe znaki ciągu, a w X11-Basic tylko 1 znak. Dlatego użyto funkcji RIGHT$.
Poniżej wersja bez łańcuchów i FOR:
Function fibo(n%) If n% <= 2 Return (n%=0) + 1 EndIf l% = LogB(n%) ! (ilość cyfr n%) - 1 b% = Bset(0, l% - 1) ! ustawienie l%. bitu na 1 q1% = 1 q2% = 1 q3% = 0 While b% t% = q2% * q2% q2% = q2% * (q1% + q3%) q1% = q1% * q1% + t% q3% = q3% * q3% + t% If (n% And b%) = b% q3% = q2% q2% = q1% q1% = q2% + q3% EndIf b% = Shr(b%, 1) ! przesuwamy bit Wend Return q2% EndFunction
No i mamy wyraźne przyspieszenie do 3.2 i 1 sekundy.
Dlaczego pętla FOR działa dłużej ? Ponieważ takie pętle posiadają ukryte instrukcje i w porównaniu do pętli WHILE pętla FOR zawiera dodatkowo komendy inicjacji zmiennej oraz zmiany jej wartości. Czyli, oprócz zawartości pętli widocznej w kodzie programu, wykonywane są operacje zmiany wartości zmiennej, sprawdzania warunku wyjścia z pętli i skoku na jej początek.
Do tej pory działaliśmy na liczbach całkowitych 32-bitowych, co pozwalało nam znaleźć co najwyżej 45. liczbę Fibonacciego. Dla uzyskania większych możemy wykorzystać tzw. arytmetykę wielkich liczb wbudowaną w X11-Basic. Sprawdźmy jaki ma to wpływ na szybkość działania naszych zoptymalizowanych funkcji. W tym celu wystarczy zmienić przyrostki odpowiednich zmiennych (a, b, f) z % na &. Wersja podstawowa wykonuje się 2x dłużej, ale wersja „macierzowa” aż 5x dłużej. Jednak dla dużych liczb wersja „macierzowa” będzie szybsza od podstawowej.
Ze zdziwieniem obserwuję w środowisku naukowym promowanie algorytmów rekurencyjnych. Jest to dla mnie niezrozumiałe, ponieważ „stara szkoła” zalecała unikanie rekurencji. Algorytmy rekurencyjne często potrzebują sporo zasobów komputera. Np. rekurencyjne (w sensie programistycznym) liczenie liczb Fibonacciego powoduje, że wielokrotnie liczone są te same liczby zanim otrzymamy oczekiwany wynik, a szybkie algorytmy sortujące oparte na rekurencji powodują w X11-Basic przepełnienie stosu dla bardzo dużych zbiorów (na szczęście posiada on wbudowaną szybką komendę SORT, która działa). Każdy algorytm rekurencyjny można przerobić na iteracyjny i zalecam to robić (lub zastąpić innym), zresztą – jeśli my tego nie zrobimy – zrobi to kompilator, niekoniecznie optymalnie.
Weźmy na przykład algorytm szybkiego sortowania, który jest przedstawiany jako typowe zadanie realizowane rekurencyjnie:
Procedure Sortuj_szybko(lewy, prawy) i = (lewy + prawy) DIV 2 piwot = d(i) d(i) = d(prawy) j = lewy For i = lewy To (prawy - 1) If d(i) < piwot w=d(i) d(i)=d(j) d(j)=w INC j EndIf Next d(prawy) = d(j) d(j) = piwot If lewy < j - 1 @Sortuj_szybko(lewy, j - 1) EndIf If j + 1 < prawy @Sortuj_szybko(j + 1, prawy) EndIf EndProcedure
Nawet trzeba się trochę wysilić, by znaleźć jego wersję iteracyjną, ale, oczywiście, taka istnieje:
Procedure Sortuj_szybko(lewy, prawy) DIM stackl(N+1) DIM stackp(N+1) s=1 stackl(1)= lewy stackp(1)= prawy repeat l= stackl(s) p= stackp(s) s= s-1 repeat ! {dziel a[l]..a[p]} i= l j= p x= d((l+p) div 2) repeat while (d(i) < x) i= i+1 wend while (x < d(j)) j= j-1 wend if (i<=j) w=d(i) d(i)=d(j) d(j)=w i= i+1 j= j-1 endif until (i>j) if (i<p) ' zadanie posortowania prawej czesci s= s+1 stackl(s)= i stackp(s)= p endif p=j until (l>=p) until (s=0) EndProcedure
Kod jest trochę bardziej skomplikowany, została dodana implementacja stosu za pomocą tablic, za to działa 3x szybciej od wersji rekurencyjnej i nie przepełnia stosu.
Dla wygody dalsze testy będę wykonywał w GFA-BASIC pozostawiając sprawdzenie jak wyniki przekładają się na X11-Basic.
Przedstawię metodę szybkiego mnożenia
Jak wiadomo – przesunięcie bitowe odpowiada mnożeniu lub dzieleniu przez daną potęgę liczby 2. Czyli działanie:
i*320można zamienić na:
SHL(i, 8) + SHL(i, 6)i działa to 2x szybciej. Dlaczego ? Odpowiedź wydaje się oczywista: operacje bitowe działają błyskawicznie, a dodawanie jest szybsze od mnożenia, ale ja odpowiadam: nie wiem... Wg testów czas wykonywania mnożenia i dodawania jest porównywalny. Co więcej – dodanie kolejnej operacji nie musi powodować spowolnienia, czasem nawet odnotowujemy minimalne przyspieszenie ! Jedyne wyjaśnienie jakie mi się nasuwa to, że kompilator dokonuje tu jakichś optymalizacji samodzielnie. Moje przypuszczenie może potwierdzać kolejny test - działanie postaci:
SHL(i, 0) * 320wykonuje się równie szybko. Czyli przesunięcie bitowe posiada „nadprzyrodzone” właściwości...
Ciekawość
nie dawała mi spokoju i sprawdziłem w X11-Basic... Tu to działa
zgodnie z przewidywaniami, czyli 2 przesunięcia i dodawanie działa
wolniej niż pojedyncze mnożenie. W dodatku przy dużych liczbach daje
błędny wynik (przekroczenie zakresu ?). Co więcej – pojedyncze
przesunięcie bitowe działa wolniej niż pojedyncze mnożenie, a to już
nie jest zgodne z przewidywaniami...
OK... zdradzę tajemnicę tego
„cudu”. Nie zadeklarowałem typu zmiennych, więc domyślnie
miały typ rzeczywisty (REAL), natomiast funkcja SHL działa na
liczbach całkowitych, więc kompilator konwertuje zmienne rzeczywiste
na całkowite, a operacje na nich wykonują się szybciej.
Przekazywanie wartości
Przekazywanie wartości do funkcji zajmuje trochę czasu. Spróbujmy policzyć Fibonacciego operując na zmiennych globalnych i użyć procedury bez przekazywania wartości zamiast funkcji. W GFA-BASIC nie widać różnicy, w X11-Basic program zamiast 5.6 sek. wykonuje się w 5 sek. Można jeszcze spróbować przekazywania przez referencje...
Arytmetyka stałoprzecinkowa
W celu przyspieszenia działania możemy spróbować zamiast arytmetyki zmiennoprzecinkowej zaimplementować stałoprzecinkową za pomocą typów całkowitych. Nie będę tu jednak tego opisywał.
Najważniejsze wnioski z testów:
Krótszy program jest często szybszy, lecz nie zawsze.
Nie zawsze komendy mające działać szybciej działają szybciej (np. SWAP, ADD).
Operacje na elementach tablic czy łańcuchów znaków zwykle działają wolniej niż na pojedynczych zmiennych.
Możemy je sprowadzić do zaleceń:
Postaraj się zmniejszyć ilość instrukcji nie zapominając o czytelności.
Stosuj odpowiednie typy zmiennych i operacje działające na jak najprostszych typach danych. Można się spodziewać, że np. działania na podstawowych typach całkowitych będą wykonywane szybciej niż na rzeczywistych (zmiennoprzecinkowych).
W miarę możliwości używaj prostych operacji bitowych.
Wprowadź dodatkowe zmienne pamiętające powtarzalne wyniki, np. tablice trygonometryczne.
Wyprowadzaj operacje poza pętlę.
Unikaj rekurencji.
Testuj wprowadzane zmiany.
Uwierz w cuda.
Dobrze jest też poznać cechy charakterystyczne danego języka, dialektu, czy nawet wersji. Np. programy w Python 2 zwykle działają szybciej niż w Python 3, ciekawostką jest też fakt, że kod wywoływany w Pythonie jako funkcja działa szybciej niż ten sam kod zawarty w głównej części programu. O różnicy między językami dobitnie świadczy fakt, że klasyczny algorytm dla ciągu Fibonacciego w Pythonie 2 działa 2x szybciej niż w GFA-BASIC-u, a wersja „macierzowo – łańcuchowa” 2x wolniej, chociaż zawiera zaledwie 3 linie w pętli. Mimo to większość podanych zaleceń powinno się sprawdzić w różnych językach.
Warto w tego typu testach zwrócić uwagę, że działanie naszego programu może być zakłócane przez procesy działające w tle, których zwykle jest sporo w systemie, i może to mieć istotny wpływ na wyniki pomiaru czasu.
Ogólnie szybkość X11-Basic rozczarowuje, wbrew zapewnieniom twórcy o jego wysokiej wydajności. Z testów wynika, że jest dużo wolniejszy od GFA-BASIC, czy Pythona. Brakuje dobrze działającego kompilatora, po kompilacji programy nie zawsze działają prawidłowo (testowana wersja: 1.25).
Przypominam, że w tym rozdziale „GFA-BASIC” oznacza 32-bitową wersję tego języka dla systemów Windows.
W ramach części praktycznej powstała prosta gra symulująca przejazd daną trasą. Zadaniem gracza jest dozowanie mocy silnika tak, by zużyć jak najmniej energii i czasu na przejazd. Profil trasy jest zapisany w pliku .CSV. Wykorzystane zostały podstawowe równania fizyczne – II zasada dynamiki: F=m*a, siła grawitacji: Fg=G*m1*m2/r^2, równania ruchu wykorzystujące metodę Eulera: x=x0+vx*dt, v=v0+a*dt oraz uproszczony wzór na siłę oporu przy danych współczynnikach oporu toczenia i oporu powietrza: F=ot*m+op*v^2.
Podczas testowania uwidoczniły się pewne różnice w wyświetlaniu grafiki w systemach Windows i Android (komenda GRAPHMODE nie działała), okna graficznego interfejsu wydają się nie praktyczne na małym ekranie, brakowało mi możliwości prostego ustawiania podstawowych kolorów za pomocą liczb całkowitych. Gra nie działała prawidłowo ani po standardowej kompilacji pod Windowsem, ani do kodu bajtowego pod Androidem, co uniemożliwia tworzenie szybkich, samodzielnie uruchamianych programów, wymagana jest obecność interpretera X11-Basic. Nie działało również automatyczne ładowanie programu do interpretera po wyjściu z edytora pod Androidem. Ogólnie interfejs graficzny wzorowany na GEM też mógłby być bardziej funkcjonalny. Mam nadzieję, że niedogodności te zostaną szybko usunięte.
Źródła:
Markus Hoffmann „X11-BASIC VERSION 1.25 User Manual”
Czasopismo „Bajtek” nr 03/1995, art. „Kopernik”, autor: Marcin Frelek
Krzysztof Ernst „Fizyka sportu”
pl.wikipedia.org/wiki/Złożoność_obliczeniowa
A. LeMothe, J. Ratcliff, M. Seminatore, D. Tayler „Sztuczki i tajemnice programowania gier.”